Programming languages are anti-social beasts: while they’re happy to communicate extensively with the operating system that launched them, they’re reluctant to talk to other programming languages. Most, reluctantly, make an exception for low-level languages, which have a natural mapping onto the low-level system ABI, most notably C. Indeed, used without qualification, the term ‘Foreign Function Interface’ (FFI) is typically assumed to refer to an interface to C, as if it was the only “foreign” programming language in existence.
Programming languages therefore resemble islands: each language defines its own community, culture, and implements its own software. Even if one wants to travel to another island, we often find ourselves trapped, and unable to do so. The only real exception to this are languages which run on a single Virtual Machine (VM), most commonly a Java VM. These days, many languages have JVM implementations, but it can sometimes seem that they’ve simply swapped their expectations of an FFI from C to Java: non-Java JVM languages don’t seem to talk to each other very much.
We’re so used to this state of affairs that it’s difficult for us to see the problems it creates. Perhaps the most obvious is the huge effort that new languages need to expend on creating libraries which already exist in other languages, an effort far greater than the core language or compiler require. Less obvious is that the initial language used to write a system becomes a strait-jacket: we almost always stick with our original choice, even if a better language comes along, even if no-one is trained in the original language, or even if it simply becomes difficult to run the original language.
Those who are brave enough, foolhardy enough, or simply desperate have three main options for escaping from this mire. First, they can manually rewrite their system in a new language. However, rewriting anything but the tiniest system from scratch in a new language is expensive – often prohibitively so – and extremely risky: it often takes years for the new system to reach parity with the old; and seemingly unimportant features are often ignored in the rewrite, only for users to rebel at their exclusion. Second, they can use translation tools to automatically rewrite their system for them. Perhaps surprisingly, this technique really works, even for very complex systems1. However, unless the two languages involved are very similar, it comes at a price: the automatically translated code rarely looks like something a human would have written. This makes maintenance of the translated systems almost impossible, and perhaps explains why these tools have seen little real-world use. Third, they can use some form of inter-process communication to have parts of the system running in different languages. The most obvious cost for this route is that splitting the system into separate chunks generally requires significant refactoring. Less obvious is that the overhead of inter-process communication is so high (depending on your system, roughly 5-6 orders of magnitude slower than a normal function call) that this technique is only practical if the resulting chunks communicate infrequently.
The outlines of a solution
At this point, I’m going to assume that you agree with me that there’s a real problem with our inability to move easily between different programming languages. Furthermore, that this is a problem that huge numbers of people (including many very large organisations) suffer from, and that existing solutions will never address. You might then wonder: why don’t we hear more complaints about this? After all, people complain endlessly about minor limitations in programming languages, frameworks, and operating systems. I think the reason for the lack of complaint is that people think the problem inevitable. Raging against it would be like raging against the River Severn’s tide: whatever you do, it’ll swallow you up and deposit you wherever it sees fit.
Recently, I’ve been involved in research – led by Edd Barrett, with assistance from Carl Friedrich Bolz, Lukas Diekmann, and myself – which, we think, suggests a new solution to this problem. If you’ve already read the accompanying paper, then parts of this blog will be familiar, although I hope there’s enough new things to keep you interested: relative to the paper, I’m going to give a bit more motivation and background, and focus a little less on some of the most minute details.
In essence, what we’ve done is to compose (i.e. glue) together two real-world programming languages – PHP and Python 2.x2 – and show that users can move between them seamlessly. We did this by composing two meta-tracing interpreters together, such that, at run-time, the two languages not only share the same address space, but that a single JIT compiler operates across them. Building atop a (somewhat traditional) FFI between the two languages, we allow users to embed syntactic fragments of each language inside the other (e.g. one can embed Python functions in PHP and vice versa, and nest those embeddings arbitrarily deep), and for those fragments to interact as if they were written in the same language (referencing variables across languages and so on). Written down like that, it can appear somewhat intimidating, but hopefully Figure 1 shows that the resulting system, called PyHyp, is fairly intuitive.
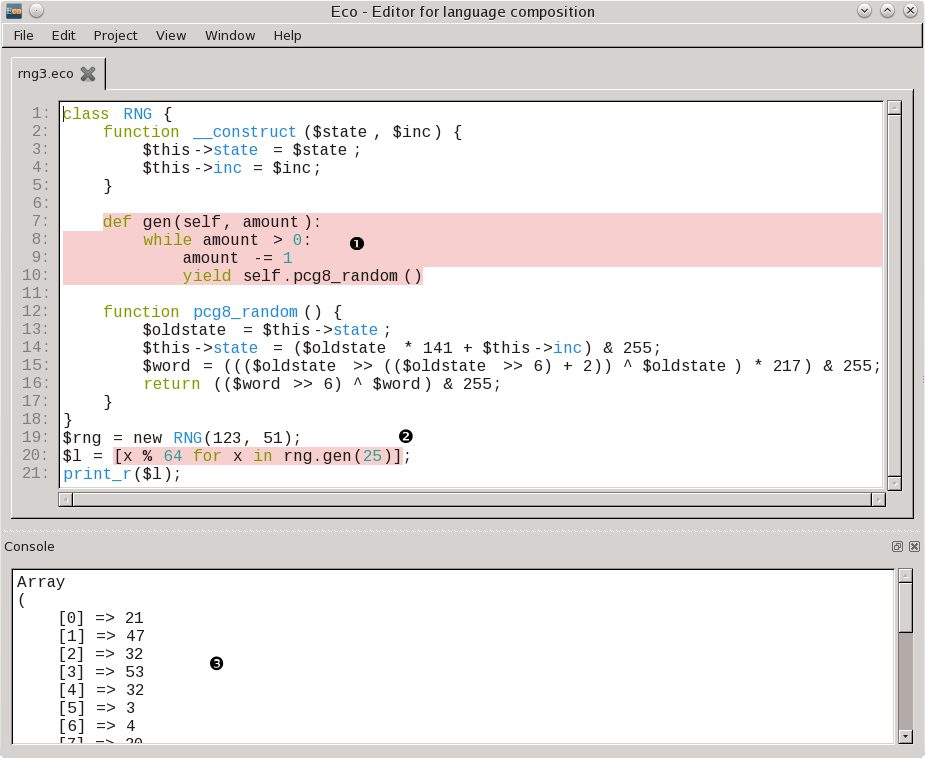
Figure 1: A PyHyp program implementing a PCG8 pseudo-random number generator, written in the Eco language composition editor. The outer (white background) parts of the file are
written in PHP, the inner (pinkish background) parts of the file in Python. ❶ A
Python language box is used to add a generator method written in Python to the
PHP class RNG. ❷ A Python language box is used to embed a Python
expression inside PHP, including a cross-language variable reference for
rng (defined in line 19 in PHP and referenced in line 20 in
Python). In this case, a Python list comprehension builds a list of random
numbers. When the list is passed to PHP, it is ‘adapted’ as a PHP array. ❸
Running the program pretty-prints the adapted Python list as a PHP array.
At this point, you might be wondering what jamming together PHP and Python really shows: after all, it’s not the first time that people have embedded one language inside another – indeed, I’ve done my share of language embeddings in the past. Most such embeddings are of a small DSL inside a larger, general purpose programming language. I’ve seen a few cases of people embedding one programming language inside another, but either the embedded language is tiny (e.g. Lisp) or only a subset of the embedded language is supported (e.g. “Java-like”). There’s nothing wrong with such approaches, but it’s never really been clear that one can sensibly embed one large programming language inside one another.
The approach we ended up taking with PyHyp shows that not only is it possible to embed large programming languages inside each other, but that the result is usable. In essence, we composed together meta-tracing interpreters, resulting in a VM that dynamically compiles composed programs into machine code; and we allow each language’s syntax to be directly embedded in the other. Optionally, one can make use of the Eco language composition editor to make the more fiddly parts of the syntactic composition easier to use. Bearing in mind the caveat that Eco is very much a research prototype, we have a reasonable expectation that this general approach will work for a wide variety of other real-world programming languages (indeed, we have also done something similar for Python and Prolog).
It’s important to realise that our approach is neither automatic nor magic. Programming languages are made by humans for humans. Composing programming languages together creates new language design issues, which humans must resolve, so that the result is usable by other humans. To be blunt, this was not something that we thought of when we started. In the end, composing real languages turned out to be a bit like assembling flat-pack furniture: some bits don’t appear to fit together very well, some take considerable effort to make sense of, and a few appear completely superfluous. We eventually came to think of these challenges as “points of friction”3: places where languages don’t play nicely with each other. These fall into two categories: semantic friction is where it’s difficult to make sense of one language’s features in the other (e.g. Python has dictionaries and lists; PHP has only dictionaries; how do we map between the two?); performance friction is where it’s difficult to make different parts of each language perform well in conjunction with each other (e.g. cross-language variable lookup is tricky to make fast, since both languages’ scoping rules are somewhat dynamic).
What the user sees
What Figure 1 hopefully makes clear is that PyHyp contains all of “normal” PHP and “normal” Python, as well as defining extra rules for composing them together. This is the result of a deliberate design goal: it is vital that normal PHP and Python code works unchanged when it is part of a PyHyp program4; we only want users to deal with PyHyp’s extra rules when they are writing cross-language code.
So, what are those extra rules? The platitudinous answer is that, as far as possible, we’ve tried to make them obvious and transparent, particularly if you use Eco. The extra syntactic rules are fairly simple: PyHyp programs always start with PHP5; wherever a PHP function is valid, a Python function can be used; wherever a PHP expression is valid, a Python expression can be used; and wherever a Python statement is valid, a PHP function is valid. The extra semantic rules are mostly simple: PHP and Python can reference variables in the outer language (semi-) lexically (we’ll look at this in more detail later); core datatypes (e.g. ints, strings) are directly converted between the two languages; collections (lists and the like) are “adapted” such that they’re almost indistinguishable from native collections; and everything else is adapted ‘generically’. In essence, an adapter is simply a wrapper around a ‘foreign’ object, such that one language can interact with objects from the other language.6
Moving things like integers and strings between the languages works simply
and naturally. Life gets a bit more complicated when you encounter areas of
semantic friction. One of the most obvious is collections: PHP has only
dictionaries (i.e. hash tables; which, confusingly, PHP calls arrays); but Python has
separate notions of lists and dictionaries. Passing a Python list or dictionary
to PHP is easy: it can only be adapted as a PHP array. The opposite direction
is more challenging, as Python lists and dictionaries have substantially
different semantics (e.g. lists are ordered, whereas dictionaries are unordered).
To most people, it seems “obvious” that if we pass a PHP dictionary
which is list-like (i.e. has integer keys from 0, 1, 2, 3 … n) to Python then it should be adapted as a Python list,
and indeed our first attempt did just this. However, since both Python (via
an adapter) and PHP point to the same underlying PHP array, later mutation
can make that PHP array turn into something
that isn’t list-like (e.g. by adding a key "woo"), at
which point the list adapter would be at best misleading, and at worst,
incorrect. We therefore ended up taking a different, safer, tack: a PHP
dictionary passed to Python is always initially adapted as a Python dictionary.
If the user knows for sure that the PHP dictionary really is, and always will
be, list-like, then they can obtain a list adapter from the dictionary adapter.
As well as the normal dictionary operations, dictionary adapters expose an extra
method to_list()7
which returns a Python list adapter pointing to the underlying PHP dictionary.
Of course, this doesn’t free us from the possibility of the underlying PHP
dictionary becoming list-like — the list adapter continually checks that
the underlying dictionary is still list-like, throwing an exception if that is
no longer true.
Those readers familiar with PHP might have noticed the implicit assumption above that PHP arrays are mutable. In fact, they are immutable: appending an item, for example, copies the underlying array, adding an extra item to the copy. Indeed, nearly all PHP datatypes are immutable with the exception of user objects (i.e. instances of classes) and references. This latter data type is a mutable reference to another object (i.e. it is a boxed pointer which can point to different objects over time). References can be used to give the illusion that data types such as arrays are mutable. Instead of passing an array around directly, one passes around a reference; when appending an item to an array wrapped in a reference, for example, one simply updates the reference to point to the new array. PHP has somewhat complex rules for automatically wrapping data types but, simplifying somewhat, functions can say that their parameters must come wrapped in a reference; non-references are automatically wrapped in a reference. Since Python users expect lists and dictionaries to be mutable, we would therefore have an uncomfortable instance of semantic friction if adapted PHP arrays were sometimes mutable, sometimes immutable. PyHyp therefore defines that passing an array from PHP to Python automatically wraps it in a reference if it is not already so. Doing so is natural from both PHP and Python’s perspective.
I could go on, because PyHyp resolves a number of other instances of semantic friction, but hopefully you believe the following: even when the two languages involved in PyHyp didn’t appear able to play together nicely, we were nearly always able to find a satisfying design to resolve the problem. However, in a few cases, there simply isn’t a sensible way to fit the two languages together. For example, Python functions can be called with keyword parameters, but PHP has no equivalent notion, and we couldn’t conceive of a usable design that would work around this fact. Therefore, trying to call a PHP function with keyword parameters from Python raises a run-time error.
How the run-time works
At this point, it’s hopefully fairly clear what the semantics of PyHyp are, but how are they implemented? Fundamentally, we do something very simple: we glue together interpreters. However, doing so naively would lead to terrible performance, so we use meta-tracing interpreters. Meta-tracing is a way of creating a VM with a JIT compiler from just a description of an interpreter. As I said in an old blog article, this is a fascinating idea, because it turns programming language economics upside down: you can get a fairly fast language implementation for not a great deal of effort8. At the time of writing, the main extant meta-tracing language is RPython (if you think of it as Java-ish semantics with Python syntax, you won’t be too far off the mark), which is what we used.
Whilst writing a really high-quality meta-tracing interpreter from scratch is
a lot easier than writing a really high-quality manual JIT compiler, it’s still
more work than we wanted to take on. We therefore took two off the shelf
interpreters — PyPy, a complete implementation of Python 2.x and HippyVM a reasonably, but
definitely not fully complete implementation of PHP9
— and joined them together. Although there was a little bit of messing
around to get this to work (mostly because HippyVM and PyPy both expect to be
the sole program being compiled and run), it’s fairly easy to do. Simplifying
somewhat, PyHyp’s main function is that of HippyVM’s: HippyVM imports
parts of PyPy and calls them as necessary (and PyPy can call back to HippyVM
etc.). From the perspective of a meta-tracer such as RPython, our “HippyVM that imports PyPy”
interpreter is no different than any other interpreter. In other words,
just because we know it contains two constituent interpreters doesn’t mean
that meta-tracing knows or cares – it’s just another interpreter (albeit
the largest ever compiled with RPython). That means that the two constituent
interpreters run in the same address space, share a garbage collector, and
share a JIT compiler.
At a low-level, PyHyp defines a fairly standard FFI between PHP and Python.
For example, PHP code can import and call Python code as in the following example,
where PHP code imports Python’s random module and then calls its
randrange function:
$random = import_py_mod("random"); $num = $random->randrange(10, 20); echo $num . "\n";
This simple example immediately raises the question of how Python’s
random module and the Python int returned by randrange
are represented in HippyVM. In essence, small immutable data-types
(e.g. ints and floats) are directly translated between the two languages
(e.g. passing a Python integer to PHP causes a PHP integer to be created).
All other data-types are represented by an adapter which points back to
the original object; all operations performed on the adapter are transparently forwarded to
the original object. For example, passing a Python user object to PHP
creates a PyAdapter in PHP: attempting to access an attribute in
the adapter forwards the request to the underlying object. Passing an adapted
object back to the language it came from simply unwraps the adapter, so that they
don’t gradually pile-up on top of each other.
Looking at the implementation of this can help make things clearer.
In the above example, the import_py_mod function returns a
Python module object which is adapted in PHP as a W_PyModAdapter.
Looking up the randrange “method” returns a Python function
object which is adapted as a W_PyCallable. Calling that adapter in PHP
causes execution to pass to the underlying Python randrange
function. As this may suggest, both PHP and Python have a number of adapters.
Some adapters make data-types appear more natural in the other language; others
are useful for performance; and the ‘generic’ catch-all adapter ensures
that every data-type in each language can be adapted.
![]()
Figure 2: Showing that adapters are transparent, with output from running
the program in the right hand (‘console’) pane. Passing a PHP array to Python
creates a dictionary adapter: querying the adapter its type returns Python’s
dictionary type. Lines 2 and 3 clearly show that the type of the adapted PHP
array, whether as a Python list or dictionary, is indistinguishable from native
Python objects. Even identity checks are forwarded: although
id_check is passed two separate adapters, the two identity checks
work as expected.
This simple model of adapters has a number of advantages: they’re simple to
implement; flexible in terms of
reducing semantic and performance friction; and, as Figure 2 shows they’re almost entirely transparent (even object identity checks are
forwarded). In order to implement them, we had to invasively modify both HippyVM
and PyPy. For the example above, we needed to add Python adapters to HippyVM, and
alter PyPy so that Python objects can adapt themselves into PHP. Simplifying
slightly, both HippyVM and PyPy have similar data-type hierarchies: both have
classes called W_Root that the various data-types inherit from. We
thus have to provide an (overridable) way for Python objects to create an
appropriate adapter for PHP, and the adapters themselves. A simplified version
of the relevant RPython code looks as follows. First the modifications to HippyVM:
# HippyVM: hippy/module/pypy_bridge/py_adapters.py from hippy.objects.base import W_Root as W_PhRoot class W_PyGenericAdapter(W_PhRoot): def __init__(self, py_inst): self.py_inst = py_inst … def lookup(self, attr_name): return self.py_inst.lookup(attr_name).to_php() def to_py(self): return self.w_py_inst
and second the modifications to PyPy:
# PyPy: pypy/interpreter/baseobjspace.py import py_adapters class W_Root: … def to_php(self): py_adapters.W_PyGenericAdapter(self)
As this code hopefully suggests, when a Python object (an instance of
W_Root) is passed to PHP, its to_php method is called;
that returns a W_PyGenericAdapter, which is a class in PHP’s object
hierarchy. If the adapter is passed back to Python, the original object is
unwrapped and passed back to Python.
As a rough measure of size, PyHyp adds about 2.5KLoC of code to PyPy and HippyVM (of which adapters are about 1.4KLoC). This is a reasonable proxy for complexity: PyHyp inherits most of the lengthy implementation work for free from HippyVM and PyPy. It may be interesting to note that we added 5KLoC of tests, which shows that much of the effort went into working out what what we wanted to see happen.
Syntactic interactions
At a low-level PyHyp composes the two languages through dynamic compilation of Python code (and of PHP code nested inside Python), but it’s too ugly for anyone in their right mind to want to use directly. By using language boxes and the Eco language composition editor, we can make syntax composition pleasant. For the simple case of dropping a Python function or expression into a PHP program, there’s little to add beyond what is obvious from Figure 1.
Things get more interesting when you want Python and PHP to syntactically
interact. What does that even mean? In PyHyp’s case, it means that Python and
PHP can reference variables in the other language. For example, if PHP defines a
variable x then a suitably scoped Python language box can reference
that variable x. In the common case, this feature is simple and
natural, but digging a bit deeper reveals real challenges. In essence, these
boil down to the fact that neither PHP 5.x and Python 2.x have, from a modern
perspective, particularly great scoping rules. Neither language is fully
lexically scoped (both can add variables to a scope at run-time) and neither
fully implements closures (Python emulates closures for reading variables, but
this illusion doesn’t deal with assignment to a variable in a parent
function). In addition, PHP has 4 separate global namespaces (one
each for functions, classes, constants, and variables), each of which is shared across all
source files (PHP includes, in a C sense, files rather than imports modules).
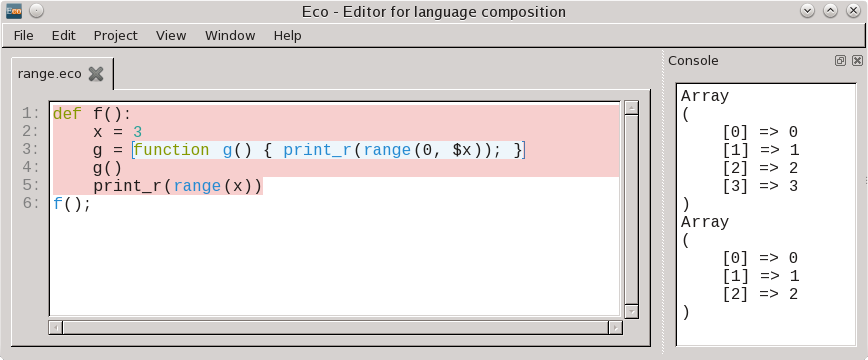
Figure 3: Cross-language variable referencing, showing some of the design
challenges in finding good cross-language scoping rules. The inner PHP language
box references PHP’s range function (inclusive in both its
parameters); the Python language box references Python’s range
function (inclusive in its first, but exclusive in its second, parameter); the
Python language box references PHP’s print_r function.
These details meant that, when we started looking at a design for
cross-language variable scoping, we didn’t really know where to start: it’s
something that, as far as we know, no-one has ever attempted before; and we
appeared to have picked two languages with different, cumbersome,
scoping rules. We quickly discovered that a bad design leads to
subtle bugs. Figure 3 shows my favourite example of
something. Both PHP and Python define global functions
called range(f, t) which
generate a list of numbers from f to t. PHP’s
range is inclusive so range(0, 3) generates [0,1,2,3];
Python’s range is exclusive on its second argument
so range(0, 3) generates [0,1,2]. That means that if
Python or PHP code references the other language’s range function
then odd things happen (and yes, we discovered this the hard way). A simple solution might
be to say that each language can only reference its own global variables, but
what happens when Python wants to use PHP’s print_r function
(which pretty prints PHP data-structures differently than Python’s equivalents)?
The eventual design10 we settled upon deals with such
nasty corner cases, but (hopefully) is still simple enough to comprehend. First,
within a language box, each language’s variable scoping rules are unchanged.
When a variable is referenced that is not found in the current language box,
then a binding is searched for in the following order. First, the lexical chain
of language boxes is recursively searched (from inner to outer) for a binding.
Second, if no match has been found, the ‘host’ language box’s globals are
searched (i.e. if a Python language box references range, and no
outer language box defines a binding for this variable, then Python’s global
variables are searched first). Third, the other language’s globals are searched
(which is how Python is able to access PHP’s print_r function).
Finally, if no match has been found, an appropriate error is raise.
One complication is PHP’s multiple global namespaces: in PHP, one can define a
function, a class, a constant, and a variable all called x. In
PHP, syntactic context disambiguates which namespace is being referred to (e.g.
new x() searches for a class called x whereas
x() searches for a function of that name). There are no equivalent
syntactic forms in Python, so PyHyp searches the global namespaces in the
following order, returning the first match: functions, classes, constants, and
variables11.
From an implementation point of view, we needed about 250LoC to add the cross-language scoping rules. Making things run fast (remember that both language’s lookup rules are entirely dynamic) was a bit more tricky but, once we’d got a good design, not hugely difficult.
At this point you may be wondering why we went to such bother to design
cross-language scoping rules. After all, previous language compositions have
nearly always done without such a feature. Our reasoning is fairly simple:
sometimes it’s convenient to use one language over the other, but not
necessarily at the level of converting one function at a time. In such cases,
being able to migrate a single line can be useful. Figure 1 gives a simple example: the Python language box on line 20 allows an
interaction with the gen function that would be horribly verbose if
it was done in PHP. As soon as you want to be able to mix languages on a
line-by-line level, it’s inevitable that you will want to reference variables
across the languages, and thus that you need to define cross-language scoping
rules.
Performance
Let’s assume that you’re now prepared to believe that PyHyp is a useful, innovative, fine-grained composition of two languages: all is for naught if PyHyp programs are slow. How do we tell if PyHyp is slow? The answer seems simple: benchmark mono (i.e. written in either Python or PHP) vs. PyHyp programs. The reality, unfortunately, is somewhat messier: no-one really knows how to reliably write good benchmarks; when a good benchmark is written, programming language implementers have a tendency to optimise specifically for it, reducing its use as a good measure12; and we don’t yet know how to produce high-quality statistics for many types of real-world executions13. As icing on the cake, anyone who’s sufficiently practised at creating benchmarks (and who, like me, is also sufficiently evil) can can create a seemingly reasonable benchmark that just so happens to show the result they want to. That said, it’s nearly always the case that some benchmarks are better than no benchmarks — just remember the above caveats when interpreting the results!
The first problem we had for benchmarking our composition is that not only were there no available PyHyp benchmarks, but there weren’t even good guidelines for how to go about creating composed benchmarks. We therefore created a series of small, focussed benchmarks that concentrate on a single feature at a time, as well as adapting several classic (relatively speaking larger) microbenchmarks. In essence, for each benchmark we created several variants: mono-PHP; mono-Python; ‘outer’ PHP with ‘inner’ Python; and ‘outer’ Python with ‘inner’ PHP. For example, for the ‘outer’ PHP with ‘inner’ Python benchmarks, we took a PHP benchmark (e.g. DeltaBlue), keeping constants, variables, and classes in PHP, but translating methods into Python. Figure 4 shows an example. The aim with these benchmarks is to get a good idea of the costs of the composition when one frequently crosses the barrier between languages.
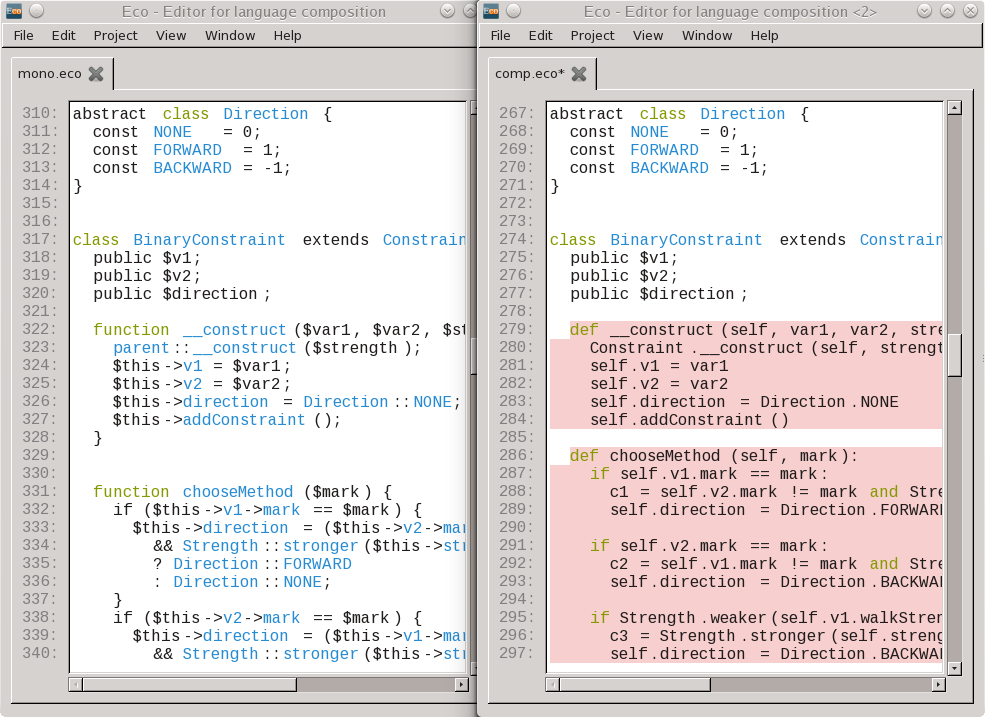
Figure 4: The DeltaBlue benchmark. On the left is a mono-PHP version. On the right is a composed version: only functions and methods have been translated into Python, with everything else (including classes, constants etc.) remaining in PHP.
If you want to see the full results, I suggest reading Section 7.3 of the paper. However, for most of us, a summary of the interesting results is probably sufficient. Since PyPy is nearly always faster than HippyVM, we can tighten our definition of “is it fast enough”, by comparing PyHyp’s performance to PyPy’s. The geometric mean slowdown of PyHyp relative to Python is 20% (1.2x) and the worst case is about 220% (2.2x). Though the latter figure isn’t amazing, bear in mind that it’s the worst case — on average, these benchmarks suggest that that PyHyp’s performance is more than good enough to be usable. Indeed, in many cases PyHyp’s performance is better than the standard C-based interpreters used for languages such as Python and Ruby!
So, why is the performance good? First, there can be little doubt that small benchmarks flatter (meta-)tracing — I would expect larger programs to see more of a slowdown, though it’s difficult to guess at how much of a slowdown that might be. Second, the most important factor in enabling good optimisations in tracing is inlining, which we were able to enable across the two languages fairly easily. Third, the major overhead that PyHyp’s composition imposes at run-time are adapters: most non-primitive objects that cross between the two languages have an adapter created. Thus we might expect that some parts of a program will require doubling memory allocation, since each object will require an adapter. In most traces which contain parts from both PHP and Python, the vast majority of adapters are created, used, and implicitly discarded within the trace. The trace optimiser can then prove that the adapters don’t ‘escape’ from the trace and thus remove their memory allocation, and nearly all other costs associated with the adapter. Thus, in practise, the typical cost of adapters is close to zero.
Of course, there are a few cases where performance isn’t as good as we would have liked. Of the cases where we found something concrete (which isn’t all cases), we found some where RPython generates inefficient machine code for two otherwise identical traces (and no-one has quite worked out why yet). A few cases suffer from the fact that PyHyp uses a ‘proper’ non-reference counted garbage collector, which sometimes causes HippyVM/PyHyp to have to copy PHP’s immutable arrays more than one would like. There are also a few parts of PyHyp which we could more extensively optimise with a bit more effort, and I’m sure that one could fairly easily write programs which tickle parts that we haven’t yet thought to optimise. But, overall, performance seems likely to remain within “good enough to use” territory, which is the most important test of all.
Conclusions
As far as I know, PyHyp is, by some considerable distance, the most fine-grained language composition yet created. I think it shows that there is a completely different, practical solution to the problem, outlined at the start of this article, of migrating a system from an old language to a new language. I hope you can imagine someone using a PyHyp-like system to migrate a system gradually from (say) PHP to Python, even down to the level of line-by-line migration: the resulting composed program would not only run, but run fast enough to be used in production. Perhaps at some point the whole system would be migrated, and the language composition thrown away. The crucial point is that at no point is one forced to flick a switch and migrate wholesale from one language to another overnight.
Could you use PyHyp for this today? In a sense, it’s a piece of software in a slightly unusual state: it’s more polished than most research pieces of software; but real users will find many missing pieces. Most of those missing pieces are in HippyVM which, although it implements pretty much all of the PHP language, lacks many standard libraries and implements a slightly old version of PHP. Fixing this isn’t difficult, but since HippyVM is not currently under active development, it would require someone taking on maintainership, and bringing HippyVM to a higher degree of compatibility with current PHP. The good news is that PyHyp picks up additions to both HippyVM and PyPy with ease, so should work on HippyVM resume, PyHyp would benefit too.
In terms of general lessons – apart from the obvious one that PyHyp shows the plausibility of fine-grained language composition – one thing stands out to me. When we started this work, we assumed that implementing a language composition would be hard, and we concentrated our thinking on that issue. We were very wrong. Implementing PyHyp has, mostly, been fairly easy: we reused sophisticated language implementations; the modifications we needed to make were relatively small and relatively simple; and meta-tracing gave us good performance for very little effort. What caused PyHyp to occupy 12-18 months of our time was a problem we didn’t even consider at the start: friction. While we were eventually able to find good solutions to all the design problems we encountered, it took us a surprisingly long time to identify the problems, and even longer to find good solutions to some of them. Partly this is because none of us was expert in both PHP and Python (indeed, weird details in both languages can catch out even the most hardened experts). We sometimes had to base our designs on our guess about one or the other language’s semantics, and gradually refine our design through extensive test-cases. But the bigger issue was that we simply didn’t have much, if any, precedent to draw upon. I’d like to think some of the design solutions we came up with will be useful to those who undertake language compositions — and I’ll certainly be interested to see the results! In the meantime, feel free to read the PyHyp paper or download PyHyp itself.
Acknowledgements: Edd Barrett was the technical lead of the PyHyp project with assistance from Carl Friedrich Bolz, Lukas Diekmann, and myself; Edd, Carl Friedrich, and Lukas gave useful comments on this blog post, but any errors or infelicities are my own. On behalf of the PyHyp project, I’d like to thank Armin Rigo for adjusting RPython to cope with some of PyHyp’s demands, and advice on HippyVM; Ronan Lamy and Maciej Fijałkowski for help with HippyVM; and Jasper Schulz for help with cross-language exceptions. This work would not have been possible without funding from EPSRC (the Cooler and Lecture projects) and, for early versions of Eco, Oracle Labs. I am grateful to both organisations!
Footnotes
I remember reading Really Automatic Scalable Object-Oriented Reengineering, which describes a system
for translating large C system to Eiffel. Although I had seen a couple of
commercial systems tackling “old” languages (e.g. Fortran to Java), I was
sceptical that a paper at an academic conference would tackle anything very
hard. I was thus impressed when I saw that wget was translated
automatically: it’s not a small program. I was stunned when I saw that Vim was
translated, even down to things like signal handling. I also can’t mention this
paper without noting how beautifully written it is: it’s rare to see authors put
so much care into making the reader’s journey through the paper a pleasant
one.
I remember reading Really Automatic Scalable Object-Oriented Reengineering, which describes a system
for translating large C system to Eiffel. Although I had seen a couple of
commercial systems tackling “old” languages (e.g. Fortran to Java), I was
sceptical that a paper at an academic conference would tackle anything very
hard. I was thus impressed when I saw that wget was translated
automatically: it’s not a small program. I was stunned when I saw that Vim was
translated, even down to things like signal handling. I also can’t mention this
paper without noting how beautifully written it is: it’s rare to see authors put
so much care into making the reader’s journey through the paper a pleasant
one.
Why PHP and Python? Partly because we had to start somewhere. Partly because we had off-the-shelf access to an excellent implementation of Python and a reasonble-ish implementation of PHP. Whilst you may have strong opinions about either or both of these languages, this blog is resolute in its intention to sit on the fence about their pros and cons.
Why PHP and Python? Partly because we had to start somewhere. Partly because we had off-the-shelf access to an excellent implementation of Python and a reasonble-ish implementation of PHP. Whilst you may have strong opinions about either or both of these languages, this blog is resolute in its intention to sit on the fence about their pros and cons.
This term was inspired by Clausewitz’s use of ‘Friktion’. To misquote Clausewitz, everything in programming language design is simple, but even the simplest thing is difficult.
This term was inspired by Clausewitz’s use of ‘Friktion’. To misquote Clausewitz, everything in programming language design is simple, but even the simplest thing is difficult.
Language composition throws up several annoying linguistic issues. First is the term itself: composition is a long, vague, and not universally understood term. When I started my initial work in this area, I used the term because someone else did — which isn’t really a very good defence on my part. In retrospect, I would have done better to have used a plainer term like “multi-lingual programming”. Alas, by the time I realised that, we’d already used the term widely enough that changing it seemed likely to lead to more confusion. Mea culpa. The second problem is what to call the resulting programs. We used the term “composed program” for a while, but that’s hopelessly ambiguous: every program is composed from smaller chunks, whether they be in different languages or not. “Multi-lingual program” has merit, and seems a good generic term. In our specific case, we talk about PyHyp programs and PyHyp files to make clear that we’re talking about programs or files that are written using the rules of our language composition.
Language composition throws up several annoying linguistic issues. First is the term itself: composition is a long, vague, and not universally understood term. When I started my initial work in this area, I used the term because someone else did — which isn’t really a very good defence on my part. In retrospect, I would have done better to have used a plainer term like “multi-lingual programming”. Alas, by the time I realised that, we’d already used the term widely enough that changing it seemed likely to lead to more confusion. Mea culpa. The second problem is what to call the resulting programs. We used the term “composed program” for a while, but that’s hopelessly ambiguous: every program is composed from smaller chunks, whether they be in different languages or not. “Multi-lingual program” has merit, and seems a good generic term. In our specific case, we talk about PyHyp programs and PyHyp files to make clear that we’re talking about programs or files that are written using the rules of our language composition.
We could have used Python as the starting point. Or, probably more usefully, we could have allowed things to start in either language.
We could have used Python as the starting point. Or, probably more usefully, we could have allowed things to start in either language.
Adapters are very similar to the idea of proxies. However, the term ‘proxy’ often comes with the expectation that users know they’re working with proxies, and that one can distinguish proxies and the thing they point to. In most cases, PyHyp’s adapters are completely transparent, hence our use of a different term.
Adapters are very similar to the idea of proxies. However, the term ‘proxy’ often comes with the expectation that users know they’re working with proxies, and that one can distinguish proxies and the thing they point to. In most cases, PyHyp’s adapters are completely transparent, hence our use of a different term.
Having lived with this decision for 18 months or so, we think we’d probably
have done better to have first adapted PHP dictionaries as a ‘blank’
adapter which appears to be neither a list or a Python dictionary, and
forcing users to call to_list() or to_dict() on
it. The main gotcha with the current behaviour is that Python defines iteration
on dictionaries to be iteration over the keys: this means that you can end up
iterating over what you think is a list, but which is really 0, 1, 2, 3 … n.
Having lived with this decision for 18 months or so, we think we’d probably
have done better to have first adapted PHP dictionaries as a ‘blank’
adapter which appears to be neither a list or a Python dictionary, and
forcing users to call to_list() or to_dict() on
it. The main gotcha with the current behaviour is that Python defines iteration
on dictionaries to be iteration over the keys: this means that you can end up
iterating over what you think is a list, but which is really 0, 1, 2, 3 … n.
Since I wrote that article, Oracle have released Truffle. Although the low-level details are different (Truffle uses dynamic partial evaluation), the high-level goals of Truffle and meta-tracing are the same. From this article’s perspective, you can consider Truffle and meta-tracing to be interchangeable, without a huge loss of precision.
Since I wrote that article, Oracle have released Truffle. Although the low-level details are different (Truffle uses dynamic partial evaluation), the high-level goals of Truffle and meta-tracing are the same. From this article’s perspective, you can consider Truffle and meta-tracing to be interchangeable, without a huge loss of precision.
Since we started work on PyHyp, work on HippyVM has finished, partly due to a lack of funding. One thing that those of us attempting to do innovative programming language work inevitably learn is that it’s really hard to pay the bills.
Since we started work on PyHyp, work on HippyVM has finished, partly due to a lack of funding. One thing that those of us attempting to do innovative programming language work inevitably learn is that it’s really hard to pay the bills.
My vague recollection is that it took about 14 iterations to get to this point. That’s language design for you!
My vague recollection is that it took about 14 iterations to get to this point. That’s language design for you!
It might be nicer to throw an error if the same name exists in more than one of PHP’s global namespaces. However, that’s slightly complicated by PHP’s lazy class loading, which we had to work around for other reasons.
It might be nicer to throw an error if the same name exists in more than one of PHP’s global namespaces. However, that’s slightly complicated by PHP’s lazy class loading, which we had to work around for other reasons.
This is Goodhart’s Law in action.
This is Goodhart’s Law in action.
We’re working on this at the moment, but we’re not finished yet.
We’re working on this at the moment, but we’re not finished yet.