Also available as: PDF.
Translations: English.
Еksperimentalna procena softverske metrike pomoću automatizovanog prerađivanja koda
SAŽETAK
O softverskoj metrici se može mnogo toga pronaći u literaturi, ali nije sasvim jasno kako su te metrike povezane jedna s drugom. Mi predlažemo novu eksperimentalnu tehniku, zasnovanu na istraživačkom prerađivanju koda, koja vrši procenu metrika softvera i ispituje njihov međusobni odnos. Naš cilj nije da unapredimo program koji se prerađuje, već da ispitamo softverske metrike koje vode automatizovano prerađivanje kroz ponavljane eksperimente prerađivanja. Primenjujemo naš pristup na pet popularnih povezanih metrika pomoću osam Java sistema iz realnog vremena, uključujući 300.000 redova koda i preko 3.000 prerađivanja. Naši rezultati pokazuju da se povezane metrike ne slažu jedna s drugom u 55% slučajeva, i pokazuju kako se naš pristup može iskoristiti za otkrivanje novih i iznenađujućih uvida u metriku softvera koja se ispituje.
We apply our approach to five popular cohesion metrics using eight real-world Java systems, involving 300,000 lines of code and over 3,000 refactorings. Our results demonstrate that cohesion metrics disagree with each other in 55% of cases, and show how our approach can be used to reveal novel and surprising insights into the software metrics under investigation.
1 UVOD
Metrika se koristi i implicitno i eksplicitno da bi se izmerio i procenio softver [43]ali je i dalje teško shvatiti kako proceniti samu metriku. Raniji radovi iz domena metrike predlagali su formalnu aksiomatsku analizu [45], iako i taj pristup ima problema i ograničenja [18] , i može proceniti samo teoretska metrička svojstva, a ne i njihove praktične aspekte.
U ovom radu predstavićemo novi eksperimentalni pristup proceni metrike, zasnovan na automatizovanom istraživačkom prerađivanju koda. Neobično je da mnoge metrike podrazumevaju merenje istih aspekata kvaliteta softvera, a ipak mi ni na koji način ne možemo proveriti takve tvrdnje. Na primer, u literaturi su predstavljene mnoge metrike koje imaju za cilj merenje softverske kohezije [9 11 26 33 20]. Kada bi ove metrike merile ista svojstva, tada bi morale da proizvedu slične rezultate. To postavlja neka važna, ali neprijatna pitanja: kako se rezultati metrika koje podrazumevaju merenje istih kvaliteta softvera mogu uporediti jedni s drugima? Da li se metrike koje mere ista svojstva mogu razići i u kolikoj meri se mogu razilaziti? To su važna pitanja, jer se ne možemo osloniti na skup metrika u proceni svojstava softvera ako ne možemo utvrditi čak ni stepen do kojeg se one ne slažu, niti imamo načina da odredimo najverovatniji slučaj najvećeg neslaganja. To su obično neprijatna pitanja jer, uprkos nekoliko decenija istraživanja i praktičnog rada sa softverskim metrikama, i dalje nema odgovora, niti postoji bilo kakav opšteprihvaćeni pristup za bavljenje njima.
U ovom radu govorimo o tom problemu uvodeći eksperimentalnu tehniku ne bismo li odgovorili na ta pitanja. Naš pristup primenjuje automatizovano prerađivanje koda na program, neprestano mereći vrednosti brojnih metrika, pre i posle primene svakog prerađivanja. Na taj način moguće je napraviti empirijske opservacije o odnosima između metrika. Kada se par metrika ne slaže sa izmenama koje uvede prerađivanje, mi ispitujemo uzroke konflikta kako bismo dobili detaljniji uvid u razlike između samih metrika.
Procenjujemo naš pristup u pet široko primenjivanih kohezionih metrika. Koristimo istraživačku platformu za prerađivanje, vođenu metrikom - Code-Imp, koja može primeniti veliki broj prerađivanja bez intervencije korisnika. Korišćenjem Code-Imp platforme ostvareno je preko 3.000 prerađivanja na osam ne-trivijalnih Java programa iz realnog vremena, koji su ukupno obuhvatali preko 300.000 redova koda. Za svako prerađivanje računamo prvobitne i naknadne vrednosti kohezionih metrika i analiziramo rezultate kako bismo dobili kvantitativno i kvalitativno poređenje metrika koje se procenjuju.
Najvažniji doprinosi ovog rada su sledeći:
- Predstavljanje novog pristupa analizi metrike na istom nivou izvornog koda. Tako se realizuje pristup ispitivanju metrike koji angažuje istraživačko prerađivanje, što su po prvi put predložili Harman i Clark [25] , a koje je dosad ostalo nerealizovano.
- Primer koji pokazuje kako naš pristup otkriva da naizgled slične metrike mogu biti u konfliktu jedna s drugom i tačno određuje uzrok konflikta, na taj način obezbeđujući nov uvid u razlike između metrika.
- Određivanje broja nedokumentovanih anomalija u utvrđenoj kohezionoj metrici, što pokazuje upotrebljivost našeg pristupa kao sredstva za ispitivanje metrika.
Rad je organizovan na sledeći način. U Odeljku 2 detaljnije opisujemo naš eksperimentalni pristup, a u Odeljku 3 naglašavamo platformu koju koristimo u ovom radu za izvođenje istraživačkog prerađivanja. U Odeljku 4 opisujemo naše početno ispitivanje toga kako se skup softverskih metrika menja pod uticajem prerađivanja, što vodi ka Odeljku 5 u kojem je detaljnije izloženo empirijsko poređenje između dve određene kohezione metrike. Odeljak 6 opisuje povezani rad i, na kraju, Odeljak 7 daje zaključke i opisuje budući rad. .
2 MOTIVACIJA I PRISTUP
Motivacija za ovaj rad proistekla je iz želje da se “animiraju” metrike i ispita njihovo međusobno ponašanje u praktičnom podešavanju. Pojedinačna primena softvera omogućava samo jedan skup metričkih merenja. To očito nije dovoljno da se napravi značajno poređenje. Softversko spremište kao što je CVS obezbeđuje višestruke verzije primene softvera, čime služi kao bolja baza za upoređivanje, te su mnoge studije preuzele upravo ovaj pristup [14 2 44]. Ipak, verzija sekvenca primene softvera može uveliko varirati u smislu veličine jaza između svake verzije. Taj nedostatak kontrole nad razlikama između verzija jeste značajan suosnivački faktor u studijama koje koriste softverska spremišta za poređenje softverskih metrika.
Naš pristup ovom problemu počinje sa opažanjem da individualna prerađivanja u stilu Fowlera [22] uključuju male programske izmene sa očuvanjem ponašanja koje tipično imaju uticaj na vrednosti softverskih metrika koje se izračunavaju za program. Na primer, kod primene PushDown metode prerađivanja, metod se prenosi iz natklase na potklase koje ga zahtevaju. Natklasa može postati kohezivnija ako se prebačen metod povezuje na nedeljnoj bazi sa ostatkom klase. Ili, može postati manje kohezivna, ako prebačen metod služi za spajanje drugih metoda i polja klase. Nemoguće je tvrditi da PushDown metod prerađivanje vodi ka većoj ili manjoj koheziji, bez ispitivanja konteksta do kojeg se primenjuje. Takođe, uticaj koji će prerađivanje proizvesti na metriku zavisiće od tačne namere kohezije koju metrika objedinjuje. 5-->
Pristup obrađen u ovom radu jeste merenje skupa metričkih vrednosti u programu, a zatim i primena sekvence prerađivanja na program, mereći metrike ponovo posle svakog prerađivanja. Svako prerađivanje predstavlja malu, kontrolisanu izmenu softvera, pa je moguće identifikovati modele promena metričkih vrednosti i način njihove izmene u odnosu jedna na drugu. Za N prerađivanja i M metrike ovaj pristup pruža matricu (N + 1) × M metričke vrednosti. Kao što će biti prikazano u odeljcima 4 and 5, ova matrica se može upotrebiti za pravljenje komparativne, empirijske procene metrike i otkrivanje područja metričkih neslaganja, što može biti predmet detaljnijeg ispitivanja.
Važno pitanje u ovom pristupu jeste način na koji se generiše sama sekvenca prerađivanja. Najjednostavnije rešenje je primeniti nasumičnu sekvencu prerađivanja na program. Ipak, od većine nasumično odabranih prerađivanja može se očekivati da uzrokuju pogoršanje u softverskim metrikama, što nije preporučljivo. Da bi se to rešilo, koristimo proučavane softverske metrike za vođenje procesa prerađivanja. Na taj način, možemo osigurati da se prerađivanje primeni jedino ako se unapređuje najmanje jedna od metrika koje se proučavaju. Što je najvažnije, svako prihvaćeno prerađivanje će unaprediti koheziju programa u smislu najmanje jedne metrike, iako to može, u ekstremnim slučajevima, pogoršati situaciju za sve ostale metrike.
Ovaj istraživački pristup prerađivanju već koriste mnoge druge studije [37 38 42 27 28 41 40 29 35 32]. U ovom radu koristimo istraživačko prerađivanje ne da bismo postigli cilj u smislu prerađivanja programa, već da bismo naučili više o metrikama koje se koriste za vođenje procesa prerađivanja. Alatka za istraživačko prerađivanje koju koristimo, Code-Imp, detaljnije je opisana u Odeljku 3.
Istraživački algoritam koji koristimo za prerađivanje definisan je na slici 1. On je stohastički, jer operacija biranja pravi nasumične izbore klase koja se prerađuje, tipa prerađivanja koje će se koristiti i stvarnog prerađivanja koje će se primeniti. Potrebno je pokrenuti ovu potragu samo jednom na svakoj softverskoj aplikaciji, jer je svako primenjeno prerađivanje kompletan zaseban eksperiment. Svrha ovog algoritma je da svakoj klasi pruži jednaku šansu da se preradi i da svakom tipu prerađivanja (PullUpMethod, CollapseHierarchy itd.) da jednaku šansu da se primeni. To je važno da bi se smanjio rizik da odstupanje u procesu prerađivanja izvrši uticaj na zapaženo ponašanje metrike. Detalji fitnes funkcije nisu definisani u ovom algoritmu jer oni zavise od stvarne prirode onoga što se ispituje. Fitnes funkcija će biti definisana u odeljcima 4 and 5 , u kojima su i eksperimenti detaljnije opisani.
Unos: skup od 14 tipova prerađivanja (npr. PullUpMethod)
Unos: skup metrika koje se analiziraju
Izlaz: profil metrike
refactoring_count = 0
ponoviti
dok !empty(classes) radi
refactoring_types = skup tipova prerađivanja
dok !empty(refactoring_types) radi
refactorings.populate(refactoring_type, class)
ako !empty(refactorings) onda
refactoring.apply() (primena)
if fitness_function_improves() onda
(broj prerađivanja) nadogradnja metričkih profila
Funkcije korišćenje u ovom algoritmu definišu se na sledeći način:
Set<element>::pick:
uklanja i vraća nasumični element iz skupa
Set<Refactoring>::populate(type, class):
dodaje skupu sva zakonska prerađivanja datog tipa na datoj klasi
fitness_function_improves:
Testira da li je primenjeno prerađivanje poboljšalo softversku metriku. Detalji variraju između ispitivanja 1 i ispitivanja 2.
3 CODE-IMP PLATFORMA
Code-Imp je proširiva platforma za istraživačka prerađivanja koja pokreću metrike. Prethodno je korišćena za automatizovana poboljšanja dizajna [37 38]. Obezbeđuje prerađivanje na nivou dizajna kao što je pomeranje metoda oko hijerarhije klase, deljenje klasa i menjanje nasleđa i odnosa prosleđivanja. Ne podržava niskostepena prerađivanja koja dele ili spajaju metode.
Code-Imp je razvijen na RECODER platformi [24]
i u potpunosti podržava Javu 6. Trenutno realizuje sledeća prerađivanja: [22]:
Prerađivanja na nivou metoda
- Push Down metod (guranja):
- Pomera metod iz klase u potklase koje ga zahtevaju.
- Pull Up metod (povlačenja):
- Pomera metod iz klase/a u prvu narednu natklasu.
- Increase/Decrease Accessibility metod (umanjenja/uvećanja pristupačnosti):
- Menja pristupačnost metoda za jedan nivo, npr. javni u zaštićeni ili privatni u paket.
Prerađivanja na nivou delokruga
- Push Down delokrug:
- Pomera delokrug iz klase u potklase koje ga zahtevaju.
- Pull Up delokrug:
- Pomera delokrug iz klase/a u prvu narednu natklasu.
- Increase/Decrease Field Accessibility (umanjenja/uvećanja pristupačnosti delokruga):
- Menja pristupačnost delokruga za jedan nivo, npr. javni u zaštićeni ili privatni u paket.
Prerađivanja na nivou klase
- Izdvaja hijerarhiju:
- Dodaje nove potklase klasi C bez čvora u hijerarhiji nasleđa. Potskup potklasa C naslediće iz nove klase.
- Sakuplja hijerarhiju:
- Uklanja klasu bez čvora iz iz hijerarhije nasleđa.
- Pravi natklasu apstraktnom:
- Deklariše bezgraditeljsku klasu eksplicitno apstraktnom.
- Pravi natklasu konkretnom:
- Uklanja eksplicitnu ‘apstraktnu’ deklaraciju apstraktne klase bez apstraktnih metoda.
- Menja nasleđe za prosleđivanje:
- Menja odnos nasleđa između dve klase odnosom prosleđivanja; bivša potklasa imaće delokrug koji pripada tipu bivše natklase.
- Menja prosleđivanje za nasleđe:
- Menja odnos prosleđivanja između dve klase odnosom nasleđivanja; klasa koja se prosleđuje postaje potklasa bivše klase delegata.
Code-Imp raščlanjuje program za prerađivanje kako bi proizveo skup apstraktnih sintaksičkih stabala (Abstract Syntax Trees, ASTs). Zatim neprestano primenjuje prerađivanje na ta stabla i ponovo proizvodi izvorni kod iz stabala pošto se proces prerađivanja okonča. Code-Imp odlučuje o sledećem prerađivanju koje će se izvršiti na osnovu korišćene precizne tehnike traženja i vrednosti upotrebljenih fitnes funkcija. Proces prerađivanja može se voditi pomoću jedne od brojnih meta-algoritamskih (heuristićkih) tehnika traženja kao što su algoritam simulacije žarenja, algoritam penjanja uz brdo i genetički algoritam. U ovom radu koristićemo samo algoritam penjanja uz brdo.
Fitnes funkcija koja vodi potragu jeste računanje bazirano na jednoj ili više softverskih metrika. Code-Imp pruža dve realizacije za svaku metriku povezanu sa uključenjem ili isključenjem nasleđa u definiciji metrike. Pet kohezionih metrika se koristi u ovom radu, naime Kohezija čvrste klase (Tight Class Cohesion, TCC) [8], Nedostatak kohezije između metoda (Lack of Cohesion between Methods, LCOM5) [12], Kohezija klase (Class Cohesion, CC) [10], Kohezija osetljive klase (Sensitive Class Cohesion, SCOM [21] i Niskostepena kohezija klase bazirana na sličnosti (Low-level Similarity Base Class Cohesion, LSCC) ) [3]. Formalne i neformalne definicije ovih metrika predstavljene su na slici 2.
Kao i kod svih automatizovanih pristupa, sekvenca prerađivanja koju generiše Code-Imp ne sme da podseća na prerađivanja koja bi programer najverovatnije sam preduzeo u praksi. Ovo pitanje sada nije bitno jer se mi fokusiramo na promenu u metričkim vrednostima, a ne na promene u dizajnu koje izaziva prerađivanje.
| |
||
| LSCC(c) | = 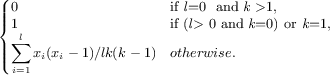 | Sličnost između dva metoda jeste skup njihovih direktno i indirektno deljenih atributa. |
| |
||
| TCC(c) | = 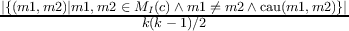 | Sličnost između dva metoda jeste skup njihovih direktno i indirektno deljenih atributa. c |
| |
||
| CC(c) | = 2∑
i=1k-1 ∑
j=i+1k 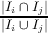 /k(k - 1) /k(k - 1) | Sličnost između dve metode jeste razmera skupa njihovih deljenih atributa i ukupnog broja njihovih pomenutih atributa. . |
| |
||
| SCOM(c) | = 2∑
i=1k-1 ∑
j=i+1k 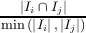 * *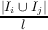 /k(k - 1) /k(k - 1) | Sličnost između dve metode jeste razmera skupa njihovih deljenih atributa i minimalnog broja njihovih pomenutih atributa. Intenzitet povezanosti jednog para metoda je jači ukoliko takav par uključi više atributa. |
| |
||
| LCOM5(c) |
= 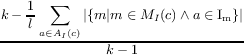 | Meri nedostatak kohezije klase u smislu proporcije atributa koje svaki metod pominje. Za razliku od drugih metrika, LCOM5 meri nedostatak kohezije tako da niže vrednosti pokazuju bolju koheziju.. |
| |
||
| |
|
|
| Gore: c je posebna klasa; MI(c) je skup metoda realizovanih u c; AI(c) je skup atributa realizovanih u c; k and l su brojevi metoda i atributa realizovanih u klasi c respectively; Ii je skup atributa koje pominje metod i; xi je broj u ith koloni metod-atribut referenca (Method-Attribute Reference, MAR) matrice, MAR(i,j) ima 1 ako ith metod direktno ili indirektno upućuje na jth atribute; cau(m1,m2) ima 1 if m1 ako m2 zajednički koristi atribut klase c . |
|
|
|
|
.
4 ISPITIVANJE I: ОPŠTA PROCENA KOHEZIJE METRIKE
U ovom ispitivanju krećemo u prerađivanje preko polja raznovrsnih kohezionih metrika koje se posmatraju. Naš cilj je da dođemo do sveukupnog razumevanja načina na koji se metrike menjaju i da pronađemo moguće nepravilno ponašanje koje se može dalje ispitivati.
Kao što je objašnjeno u Odeljku 2, nasumična primena prerađivanja obično će izazvati pogoršanje u svim kohezionim metrikama. Stoga koristimo istraživanje koje kruži kroz klasu programa koji se ispituje, kao što je opisano na slici 1, i pokušavamo da pronađemo prerađivanje na klasi koja unapređuje barem jednu od metrika koje se proučavaju. Potraga će primeniti prvo prerađivanje na koje naiđe, a koje unapređuje metriku. Druge metrike se takođe mogu poboljšati, ostati iste ili se pogoršati. S obzirom da je ovu fitnes funkciju lako unaprediti, dobijamo duge sekvence prerađivanja neophodne za izvlačenje zaključaka o odnosima između metrika.
Metričke formule na slici 2 pokazuju kako se izračunava metrika za pojedinačnu klasu. Za merenje kohezije više klasa, tj. celog programa, koristimo formulu za otežanu koheziju, baziranu na formuli koju su predložili Briand i Al Dalla [2]:
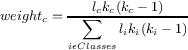
gde je težinan težina dodeljena koheziji klase n, ln je broj atributa u klasin, a kn je broj metoda u klasi n. U slučaju gde je kc jednako kc 1, brojač u formuli postaje l. Ovo je formula koju koristimo za LSCC. Za ostale metrike prekrajamo ovu formulu tako da dobije smisao za tu metriku
Većina softverskih metrika po prirodi je redna, tako da se svaka formula koja ih procenjuje teoretski dovodi u sumnju. Ipak, naše iskustvo pokazuje da te metrike nisu daleko od toga da se nađu na intervalnoj skali, pa je rizik da se one tretiraju kao interval mali u odnosu na prednosti koje to donosi. Briand i Al su dali sličan argument za upotrebu parametričkih metoda za podatke sa redne skale [11].
| System | Description | LOC | #Classes
|
| JHotDraw 5.3 | Graphics | 14,577 | 208 |
| XOM 1.1 | XML API | 28,723 | 212 |
| ArtofIllusion 2.8.1 | 3D modeling | 87,352 | 459 |
| GanttProject 2.0.9 | Scheduling | 43,913 | 547 |
| JabRef 2.4.2 | Graphical | 61,966 | 675 |
| JRDF 0.4.1.1 | RDF API | 12,773 | 206 |
| JTar 1.2 | Compression | 9,010 | 59 |
| JGraphX 1.5.0.2 | Java Graphing | 48,810 | 229 |
| JHotDraw | JTar | XOM | JRDF | JabRef | JGraph | ArtOfIllusion | Gantt | All | |
| (1007) | (115) | (193) | (13) | (257) | (525) | (593) | (750) | (3453) | |
| LSCC | 96 | 99 | 100 | 92 | 99 | 100 | 99 | 96 | 98 |
| TCC | 86 | 53 | 97 | 46 | 61 | 72 | 84 | 71 | 78 |
| SCOM | 79 | 70 | 93 | 92 | 79 | 89 | 77 | 80 | 81 |
| CC | 100 | 98 | 100 | 92 | 99 | 100 | 100 | 99 | 100 |
| LCOM5 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 99 | 100 |
4.1 Rezultati i analize
Ovaj proces prerađivanja primenili smo na osam otvorenih kodova Java projekata predstavljenih u Tabeli 1. U svakom slučaju eksperiment se vodio pet dana ili dok se ne postigne sekvenca od 1000 prerađivanja. Ukupno 3.453 prerađivanja je primenjeno, kao što je prikazano u Tabeli 2. U početku, aplikacije su bile visoko kvalitetne, pa je za pronalaženje poboljšanja u koheziji bilo potrebno dosta vremena. JHotDraw se pokazao kao najlakši program za prerađivanje jer je njegova široka upotreba dizajn modela i bogata hijerarhija nasleđa pružila mnogo mogućnosti za prerađivanje. Obratite pažnju da u ovom radu koristimo proces prerađivanja samo da bismo ispitali svojstva metrike. Ne iznosimo nikakve tvrdnje da prerađeni program ima bolji dizajn od originalnog.. .
4.1.1 Nepostojanost
Jedan od aspekata metrike koji nam ovo ispitivanje dozvoljava da vidimo jeste nepostojanost. Nepostojana metrika je ona koja se pod prerađivanjem često menja, dok je inertna metrika ona koja se pod prerađivanjem menja veoma retko. Nepostojanost je bitan faktor u određivanju upotrebljivost metrike. Na primer, u istraživačkom prerađivanju, visoko nepostojana metrika imaće veoma jak uticaj na način daljeg postupanja prerađivanja, dok bi relativno inertnu metriku bilo besmisleno izračunavati. U kontekstu kvaliteta softvera, merenje napredovanja u dizajnu sistema pomoću skupa inertnih metrika verovatno će biti isprazno, jer su to, po definiciji, sirova merenja koja ne otkrivaju fine izmene u svojstvima koja se mere. Tabela 2 pokazuje nepostojanost 5 metrika u svakom individualnom sistemu koji se ispituje, kao i prosek u svim sistemima.
Prvo zapažanje je da su LSCC, CC i LCOM5 visoko nepostojane metrike. U 99% prerađivanja koja se primenjuju na aplikacije, svaka od tih metrika se ili povećala ili smanjila. Relativni nedostatak nepostojanosti TCC metrike je većinom zbog cau odnosa (vidi sliku 2), koji je relativno redak za neki par metoda..
Rezultati za JRDF aplikaciju su značajni. Sve metričke linije TCC su visoko nepostojane za ovu aplikaciju. Iako je JRDF jedna od većih aplikacija, na nju se ukupno može primeniti samo 13 prerađivanja, u poređenju sa 1000 i više prerađivanja koja se mogu primeniti na JHotDraw, aplikaciju slične veličine. Objašnjenje za ovo leži u prirodi aplikacije. U JHotDraw, 86% klasa su potklase, dok u JRDF ta cifra iznosi tek 6%. S obzirom da je većina prerađivanja koja Code-Imp primenjuje povezana sa nasleđem, aplikacija koja malo koristi nasleđe, pruža malo mogućnosti za preradu.
Dok određena doslednost postoji u različitim aplikacijama, JRDF primer pokazuje da, s obzirom na individualnu metriku, nepostojanost može značajno da varira između sistema. Pokušali smo da normalizujemo nepostojanost naspram ukupne nepostojanosti svake aplikacije i, dok je to donekle dokazalo doslednost, ogromno odstupanje se zadržalo. Stoga smo zaključili da nepostojanost zavisi od kombinacije metrike i aplikacije na koju se primenjuje.
| JHotDraw | JTar | XOM | JRDF | JabRef | JGraph | ArtOfIllusion | GanttProject | Average | |
| LSCC | ↑50 , 46↓ | ↑50 , 49↓ | ↑57 , 43↓ | ↑46 , 46↓ | ↑54 , 46↓ | ↑51 , 48↓ | ↑57 , 42↓ | ↑53 , 43↓ | ↑53 , 45↓ |
| TCC | ↑45 , 41↓ | ↑30 , 23↓ | ↑51 , 46↓ | ↑23 , 23↓ | ↑34 , 27↓ | ↑37 , 35↓ | ↑52 , 35↓ | ↑39 , 31↓ | ↑43 , 35↓ |
| SCOM | ↑38 , 40↓ | ↑34 , 36↓ | ↑50 , 44↓ | ↑46 , 46↓ | ↑37 , 42↓ | ↑36 , 53↓ | ↑44 , 33↓ | ↑40 , 40↓ | ↑40 , 41↓ |
| CC | ↑53 , 47↓ | ↑52 , 46↓ | ↑51 , 49↓ | ↑46 , 46↓ | ↑54 , 44↓ | ↑61 , 39↓ | ↑58 , 42↓ | ↑57 , 42↓ | ↑56 , 44↓ |
| LCOM5 | ↑51 , 49↓ | ↑50 , 50↓ | ↑48 , 52↓ | ↑54 , 46↓ | ↑49 , 50↓ | ↑41 , 59↓ | ↑56 , 43↓ | ↑50 , 50↓ | ↑50 , 50↓ |
4.1.2 Verovatnoća pozitivne promene
Tabela 2 pokazuje koliko je metrika nepostojana, ali ne pokazuje da li je nepostojanost pozitivna ili negativna stvar. U tabeli 3 dajemo takav prikaz metrike. Podsetimo se da je svako prerađivanje koje je primenjeno u ovom ispitivanju uvećalo bar jednu od kohezionih metrika. Onda postaje zadivljujuće koliko često uvećanje u jednoj kohezionoj metrici vodi na umanjenju u drugoj. Uzimajući LSCC i ArtOfIllusion kao primer, LSCC se umanjuje u 42% prerađivanja (593 ukupno). Tako je za ArtOfIllusion, 249 prerađivanja koja su poboljšali najmanje jednu od TCC, SCOM, CC ili LCOM5, kao što garantuje proces prerađivanja, izazvalo pogoršanje LSCC-a.
| LSCC | TCC | SCOM | CC | |
| TCC | 0.60 | |||
| SCOM | 0.70 | 0.58 | ||
| CC | 0.10 | 0.01 | -0.28 | |
| LCOM5 | -0.17 | -0.21 | -0.46 | 0.72 |
Ovaj model konflikta se ponavlja u celoj Tabeli 3. Kao što je rezimirano u Tabeli 4, TCC, LSCC i SCOM izvode umerenu pozitivnu korelaciju, dok CC i LCOM5 pokazuju kombinovanu korelaciju koja ide od umereno pozitivne korelacije (LCOM5 i SCOM) do jako negativne korelacije (LCOM5 i CC).
SCOM) do jako negativne korelacije (LCOM5 i CC).
Kako bismo rezimirali nivo neslaganja u jednom skupu metrika takođe smo razmotrili svako udvojeno poređenje između svakog para metrike za svako prerađivanje. Za 5 metrika imamo
(5 * 4)∕2 = 10
udvojenih poređenja po prerađivanju. Za 3.453 prerađivanja to donosi ukupno 34.530 udvojenih poređenja. Svaki par se kategorizuje na sledeći način:
Nesaglasni: Jedna vrednost se uvećava ili smanjuje, dok druga ostaje ista.
U konfliktu: Jedna vrednost se uvećava, a druga se smanjuje.
U celom skupu prerađivanja pronašli smo da su nivoi sledeći: 45% su saglasni, 17% nesaglasni i 38% u konfliktu. Cifra od 38% u konfliktu je zadivljujuća i ukazuje na to da će, u velikom broju slučajeva, ono što jedna koheziona metrika smatra poboljšanjem u koheziji, druga koheziona metrika smatrati umanjenjem u koheziji. To ima praktičan uticaj na način upotrebe kohezione metrike. Pokušaj poboljšanja softverskog sistema pomoću kombinacije kohezionih metrika u konfliktu je nemoguće - poboljšanje u smislu jedne kohezione metrike će verovatno izazvati pogoršanje u smislu druge metrike.. .
4.2 Rezime
Ovo ispitivanje poslužilo je da se pokaže neslaganje između softverskih kohezionih metrika u smislu njihove nepostojanosti i njihove sklonosti da se slažu ili ne slažu jedna s drugom. Naravno, koheziona metrika koja se u potpunosti slaže sa drugom ne radi ništa u prilog debati o koheziji. Ipak, konflikt između metrika ukazuje na to da paket kohezionih metrika ne reflektuje jednostavno različite aspekte kohezije, već reflektuje kontradiktorne interpretacije kohezija.
U cilju daljeg ispitivanja ovog konflikta, odabrali smo dve kohezione metrike, LSCC i TCC i detaljnije ih analizirali pomoću istraživačkog prerađivanja. Rezultati su predstavljeni u sledećem odeljku. .
5 ISPITIVANJE II: DETALJNA ANALIZA KOHEZIONIH METRIKA
Prvo ispitivanje pokazuje kako se istraživačko prerađivanje može upotrebiti za kreiranje širokog spektra načina na koji su metrike povezane jedna s drugom. U ovom drugom ispitivanju uzeli smo dve dobro poznate kohezione metrike, LSCC i TCC, i bliže istražili njihov odnos. Izabrali smo te dve, jer su to popularne metrike niskostepenog dizajna, sa različitim karakteristikama. TCC su 1995. objavili Bieman i Kang [8], izdržala je test vremena i pokazala se više inertnom u ispitivanju I. LSCC su 2010. objavili Briand i Al Dallal [2], i otuda ona prestavlja najnoviju interpretaciju kohezije. Za razliku od TCC, LSCC se pokazala veoma nepostojanom u ispitivanju I.
U definiciji obe ove metrike [8 2], autori su pomenuli pitanje da li nasleđe treba da se uzme u obzir prilikom izračunavanja kohezije ili ne, ali ne ulaze u detalje. Ako se nasleđe uzme u obzir, onda se kohezija klase računa kao da su sve nasleđene metode i polja takođe deo klase. Prema mišljenju autora ovog rada, to je kritično pitanje. Može se pokazati da klasa ima dve nepovezane metode, ali ako one obe pristupe istim nasleđenim metodama ili poljima, mogu u stvari biti veoma kohezivne 1. Zato uzimamo u obzir dve verzije svake od ovih metrika, normalne, “lokalne” verzije pod imenom LSCC i TCC i “nasleđene” verzije koje smo nazvali LSCCi i TCCi.
Izveli smo dva eksperimenta da bismo testirali odnose između ovih metrika. U svakom eksperimentu upotrebili smo jednu metriku da bismo pokrenuli proces prerađivanja i izmerili uticaj na drugu metriku. Eksperimenti su sledeći::
- uvećanje LSCC merenje TCC
- uvećanje TCCi merenjei
Drugi očiti eksperimenti, uvećanje TCC i merenje LSCC i uvećanje LSCC i merenje TCCi su takođe izvedeni. Rezultati su u skladu sa dole navedenim, ali smo detalje izostavili zbog nedovoljno mesta. JHotDraw je odabran za aplikaciju na kojoj će se sprovoditi ti eksperimenti, jer se u Odeljku 4 pokazala kao aplikacija koju je Code-Imp najlakše mogao da preradi.
Promenili smo fitnes funkcije koje su pokretale ispitivanje u ovim eksperimentima. U našem početnom ispitivanju u Odeljku 4 cilj je bio da se primeni što je više prerađivanja moguće kako bi se dobio ukupan uvid u međusobne metričke odnose. Sada pak, u ovom odeljku želimo da imitiramo programera koji prerađuje program pomoću kohezione metrike kao vodiča. Ako upotrebimo prosečnu koheziju klase kao fitnes funkciju, ignorisaćemo činjenicu da, iz perspektive softverskog inženjeringa, nisu sve klase jednake važnosti. Na primer, korisnije je unaprediti koheziju klase koja se često ažurira, nego koheziju stabilne klase.
Iz tih razloga upotrebili smo noviju fitnes funkciju u domenu istraživačkog prerađivanja: Pareto-optimalno ispitivanje h kroz klase programa koji se prerađuje22. Prerađivanje koje pokušava da uveća metriku prihvata se samo ako uvećava tu metriku barem za jednu klasu i ne izaziva pad u toj metrici ni za jednu drugu klasu. To je prilično ograničavajuća fitnes funkcija, ali mi smatramo da će rezultirajuća sekvenca prerađivanja najverovatnije biti prihvaćena kao korisna sekvenca prerađivanja u praksi. Dužina sekvenci prerađivanja u ovim eksperimentima je mnogo kraća od onih iz Odeljka 4, ali je dovoljne dužine da bi se trendovi primetili.
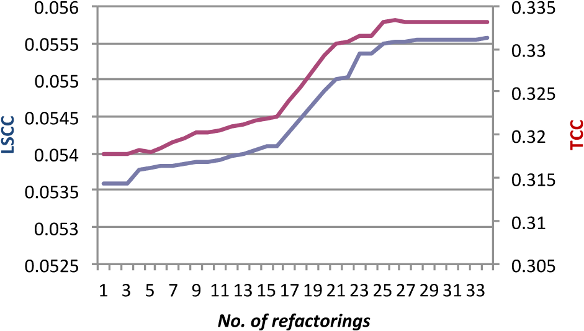
5.1 Uvećanje LSCC, merenje TCC
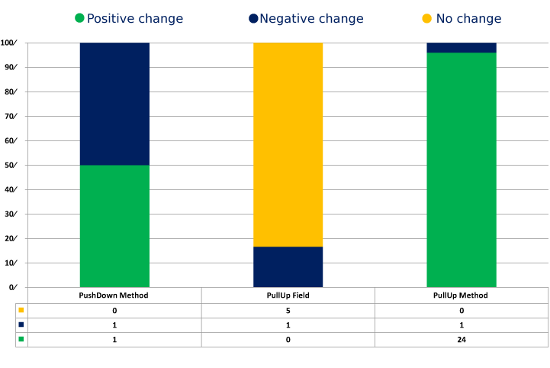
Rezultat prerađivanja JHotDraw za poboljšanje LSCC i merenje uticaja na TCC predstavljeno je na Slikama 3 i 4. Izvedeno je 33 prerađivanja i obe metrike su imale odmerena uvećanja, sa malo vidljivog konflikta (Spearmanov koeficijent korelacije 0.8). Ipak, ako bliže pogledamo prerađivanje na Slici 3, anomalija postaje očigledna. U prerađivanju 26, TCC malo pada i ostaje konstantna u sledećih 5 prerađivanja, dok se LSCC odmereno uvećava. Ovu oblast neslaganja malo bliže ispitujemo da bismo odredili šta nam govori o metrikama.
Ovaj period neslaganja javlja se tokom sekvence PullUpField prerađivanja, gde ciljana klasa nema nijedno polje. TCC je nedefinisana za klasu bez ijednog polja, tako da izgleda da pomeranje polja u takvu klasu umanjuje koheziju tako što programu dodaje klasu sa nultom kohezijom. S druge strane, iz ovog primera smo naučili da LSCC više voli da pomera polje koje je labavo povezano sa klasom (npr. koje samo jedan metod koristi direktno ili indirektno) u svoju natklasu, ako ta natklasa ima nulto LSCC merenje (ne postoje dve metode koje će pristupiti istom polju). U praksi, na to se gleda kao na štetno prerađivanje, pa smo tako otkrili slabost u LSCC metrici koja će nagraditi takvo prerađivanje. .
5.2 Uvećanje TCCi, merenje LSCCi
Rezultat prerađivanja JHotDraw za poboljšanje TCC i i merenje uticaja na LSCC i predstavljeno je na Slici 5. Izvedeno je 91 prerađivanje i, dok ima određenih slaganja u mestima, grafikon ukupno pokazuje ekstreman konflikt (Spearmanov koeficijent korelacije -0.8).
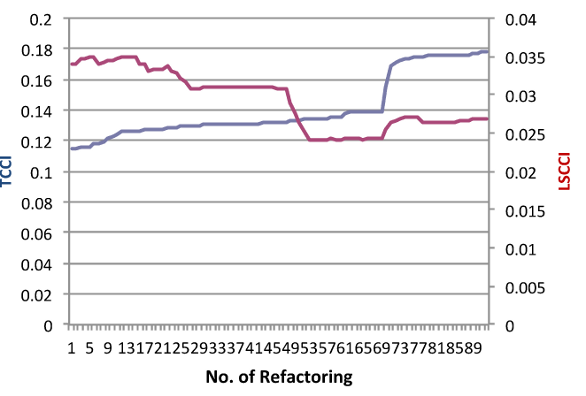
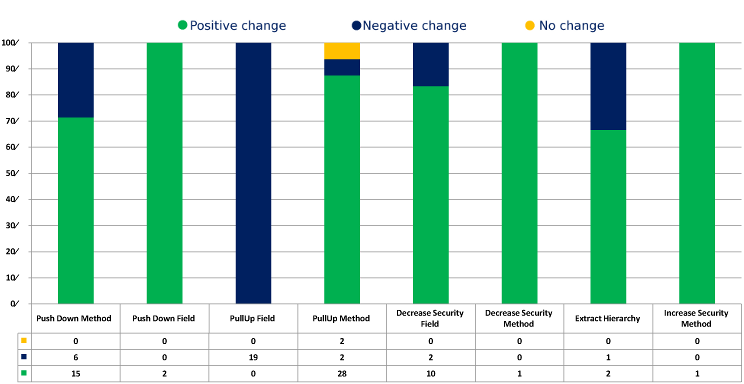
Slika 6 pruža detaljan uvid u prerađivanja i njihov efekat na LSCCi metriku. Najupadljivija osobina je da PullUp polje ima negativan uticaj na LSCC i u svakom slučaju. Negativan uticaj se ostvaruje jer se polje pomera u natklasu u kojoj nema interakcija, što umanjuje LSCCi za tu klasu. TCC i daje prednost tom prerađivanju jer, kao deo povlačenja privatnog polja u natklasu, mora biti zaštićeno, što izaziva više interakcije između zaštićenih metoda koje koriste polje u strukturi hijerarhije. Ova upotreba PullUp polja u ovom slučaju istinski poboljšava koheziju, tako da je to snaga LSCCi-a koju ona neće preporučiti.
Drugo polje konflikta je negativan efekat koji PushDown metod ima na LSCCi u šest prerađivanja. Prilikom ispitivanja tih prerađivanja, primetili smo da TCCi uvek više voli da metod boravi u klasi u kojoj je korišćen i da pristupi polju koje mu je neophodno u njegovoj natklasi (gde, naravno, ne mogu biti privatni), nego da boravi u natklasi. Ipak, LSCCi više potencira čuvanje privatnosti polja, tako da često više voli kada metod ostane u klasi polja koje koristi, osim kada taj metod koristi većina potklasa.
5.3 Rezime
U ovom odeljku koristili smo Pareto-optimalno ispitivanje kroz klase u cilju detaljnog demonstriranja načina na koji se dve metrike mogu uporediti i odudarati jedna od druge. U oba eksperimenta, LSCC vs. TCC i TCC i vs. LSCCi, pronašli smo područja slaganja i konflikta između metrika. Bliže ispitivanje područja konflikta bacilo je svetlo na aspekte metrika koji nisu odmah očigledni u njihovim formulama.
6 POVEZANI RAD
U ovom odeljku dajemo pregled povezanog rada u Istraživačkom Prerađivanju (odeljak 6.1) i Softverskoj Metrici (odeljak 6.2).
6.1 Istraživačko prerađivanje
Istraživačko prerađivanje je potpuno automatizovano prerađivanje koje pokreće meta-heurističko ispitivanje i vodi softverske kvalitativne metrike, kao što su izneli O'Keeffe i Ó Cinnéide [39]. Postojeći rad u ovoj oblasti koristi ili “direktan” ili “indirektan” pristup. U direktnom pristupu koraci prerađivanja primenjuju se direktno na program, označavajući korake iz trenutnog programa do najbližeg susednog u prostoru koji se ispituje. Rani primeri direktnog pristupa jesu radovi Williama [46] i Nisbeta [34] koji su uputili na problem paralelizacije. Nedavno su O'Keeffe i Ó Cinnéide [37 38] primenili direktan pristup problemu automatizovanja poboljšanja dizajna.
U indirektnom pristupu, program se indirektno optimizuje kroz optimizaciju sekvence transformacije koja se primenjuje na program. U ovom pristupu fitnes se izračunava tako što se sekvenca transformacije primenjuje na predmetni program i meri poboljšanje u predmetnim metrikama. Prvi autori koji su upotrebili ispitivanje na ovaj način bili su Cooper i drugi [13], koji su upotrebili polarizovano nasumično uzorkovanje kako bi ispitali prostor visokostepenih celoprogramskih transformacija za optimizaciju kompilatora. Takođe, prateći indirektan pristup, Fatiregun i drugi [16 17] pokazali su kako transformacija bazirana na ispitivanju može da se upotrebi za smanjenje veličine koda i izgradnju amorfnih isečaka programa.
Seng i drugi [42] predložili su indirektnu istraživačku tehniku koja koristi genetički algoritam u sekvencama prerađivanja. Za razliku od funkcije O'Keeffea i Ó Cinnéidea [36], njihova fitnes funkcija je bazirana na dobro poznatim merama spajanja između komponenti programa. Oba ova pristupa koristila su težinski zbir za kombinovanje metrike u fitnes funkciju, što ima praktičnu vrednost, ali je diskutabilna operacija u rednim metričkim vrednostima. Rešenje za problem kombinovanja rednih metrika predstavili su Harman i Tratt, koji su uveli koncept Pareto optimalnosti u istraživačko prerađivanje [27]. Oni su ga koristili da bi kombinovali dve metrike u fitnes funkciju i pokazali da ima nekoliko prednosti nad pristupom težinskog zbira.
Rad Sahraoui i drugih [41] je sličan našem, posebno njihova premisa da polu-automatizovano prerađivanje može poboljšati metriku. Njihov pristup podrazumeva traženje uvida u prerađivanja koja su odabrana da poboljšaju metriku. Naš pristup je obrnut: mi koristimo prerađivanja da bismo dobili uvid u (višestruke) metrike.
U nedavnom radu, Otero i drugi [40] koristili su istraživačko prerađivanje da bi preradili program tokom njegovog nastajanja, pomoću genetičkog programiranja, u pokušaju da se pronađe drugačiji dizajn koji će priznati korisnu transformaciju kao deo algoritma genetičkog programiranja. Jensen i Cheng [29] koristili su genetičko programiranje da bi pokrenuli proces istraživačkog prerađivanja koji ima za cilj da predstavi model dizajna. Ó Cinnéide i drugi koristili su pristup istraživačkog prerađivanja u pokušaju da poboljšaju ispitivost programa [35]. Kilic i drugi istražili su upotrebu različitih populacijski baziranih pristupa istraživačkom paralelnom prerađivanju, uviđajući da lokalno zrakasto ispitivanje može pronaći najbolje rešenje [32]. .
6.2 Analiza softverske metrike
Jedna od kritika koje se pripisuju upotrebi softverskih metrika jeste da one često nemaju uspeha u merenju onoga što treba da mere [20]. To je vodilo proliferaciji softverskih metrika [19], od kojih mnoge pokušavaju da mere iste aspekte koda. Ne iznenađuje ni to što je nekoliko studija pokušalo da uporedi softverske metrike kako bi se bolje shvatile njihove sličnosti i razlike. U ovom odeljku, fokusiramo se na studije koje su analizirale kohezione metrike. Najvažniji problem sa kohezijom (i njenim merenjem) je bio taj što je, za razliku od spajanja, svaka metrika koja tvrdi da meri koheziju, relativno subjektivna i otvorena za interpretaciju [15]. Većina kohezionih merenja fokusirala se na distribuciju atributa u metodama klase (i njihovim varijacijama). Ipak, nijanse različitih objektno orijentisanih jezika i činjenica da distribucija atributa može učiniti nemogućim izračunavanje kohezione metrike, znači da ne postoji nikakva pojedinačna, saglasna koheziona metrika.
LCOM metrika je predmet detaljnog promatranja [12] i više puta je pregledana zbog idiosinkrazije u svojim izračunavanjima. Poređenja između LCOM i drugih predloženih kohezionih metrika jesu uobičajena osobina empirijskih studija [1 2 3 7 8 14]. Većina novopredloženih kohezionih metrika pokušala je da poboljša prethodne metrike formiranjem linka između niske kohezije i visoke naklonjenosti greškama [2 3] ili intuitivnih zapažanja visoke kohezije i subjektivnog stava programera o tome šta čini visoku koheziju [7]; drugi su pokušali da demonstriraju teoretsko poboljšanje [1 14]. Poređenje kohezionih metrika predstavlja stalno prisutnu temu za istraživanje [30 31 44]. Na primer, metrika Kohezija među metodama klase (Cohesion Amongst the Methods of a Class, CAMC) [7] daje varijaciju na LCOM metriku time što uključuje sopstveno svojstvo u C++ u svom izračunavanju i potvrđuje se na osnovu mišljenja programera.
Al Dallal i Briand [1] ispitali su odnos između predloženih metrika, niskostepene kohezije klase bazirane na sličnosti (Low-Level Similarity-Based Class Cohesion, LSCC) i jedanaest drugih niskostepenih kohezionih metrika u smislu korelacije i sposobnosti da se predvide greške. Na osnovu studija o korelacijama zaključili su da LSCC snima sopstvene dimenzije kohezionog merenja. Četiri Java aplikacije otvorenog koda, sastavljene od 2.035 klasa i preko 200KLOC korišćene su kao osnova za njihovu studiju..
Counsell i drugi [14] predložili su novu metriku pod nazivom Normalizovana metrika Hammingove udaljenosti (Normalized Hamming Distance Metric, NHD). Autori su zaključili da je NHD bolja koheziona metrika od CAMC-a. Njihovi empirijski podaci, dobijeni iz tri C++ aplikacije, pokazali su jaku negativnu korelaciju između NHD-a i ostalih metrika. To se razlikuje od nedavne studije koju su sproveli Kaur i Singh [31] koji su istražili odnos između NHD-a, SNHD-a [14] i CAMC-a. Oni su primetili da je veličina klase zbunjujući faktor u izračunavanju CAMC-a i NHD-a.
Alshayeb je otkrio da prerađivanje ima pozitivan efekat na nekoliko kohezionih metrika u svojoj studiji o softveru otvorenog koda [6]. Ipak, u kasnijem radu je izneo da taj efekat ne mora biti uvek pozitivan na druge eksterne atribute kvaliteta softvera kao što su ponovna upotrebljivost, razmljivost, održivost, mogućnost testiranja i prilagodljivost [5]. Informaciono-teoretski pristup merenju kohezije predložili su Khoshgoftaar i drugi [4] i, dok to predstavlja novi pristup merenju kohezije, njihova metrika podleže istim kritikama kao i prethodne.
Ove studije su stvorile dublje razumevanje softverskih metrika i pokazale su da metrike sa sličnim namerama ne moraju da daju iste rezultate. Ipak, razumevanje osnovnih osobina metrike tek je prvi korak u određivanju njihove upotrebljivosti. Pristup o kojem se detaljnije govori u ovom radu preduzima naredni korak tako što kvantifikuje konflikt između metrika u cilju preciziranja glavnog uzročnika tog konflikta. .
7 ZAKLJUČCI I BUDUĆI RAD
U ovom radu koristimo istraživačko prerađivanje za novu svrhu: da otkrijemo odnose između softverskih metrika. Korišćenjem raznovrsnih tehnika ispitivanja (polu-nasumično ispitivanje, Pareto-optimalno ispitivanje na klasama) koje vode brojne kohezione metrike, u stanju smo da napravimo empirijske procene metrika. U području direktnog konflikta između metrika, ispitujemo prerađivanje koje je izazvalo konflikt kako bismo naučili više o prirodi konflikta.
U našoj studiji o 300KLOC softvera otvorenog koda pronašli smo da se kohezione metrike LSCC, TCC, CC, SCOM i LCOM5 slažu jedna s drugom u samo 45% primenjenog prerađivanja. U 17% slučajeva primećeno je neslaganje (jedna metrika se menja dok druga ostaje statična), a u 38% slučajeva otkriveno je da su metrike u direktnom konfliktu (jedna metrika se poboljšava dok se druga pogoršava). Ovaj visok nivo konflikta otkriva važnu osobinu kohezionih metrika: one ne samo da objedinjuju različite namere kohezija, već objedinjuju konfliktne namere kohezije. Ovaj ključni rezultat odbija mogućnost da se ikada kreira pojedinačna, ujedinjujuća koheziona metrika.
U tri područja konflikta između LSCC i TCC, naše analize prerađivanja vodile su do detaljnog uvida u razlike između ovih metrika (vidi odeljke 5.1 i 5.2). Ova analiza je takođe pokazala da odluka o tome da li uključiti nasleđe u definiciju kohezione metrike ili ne, nije tek pitanje ukusa, kao što se može pretpostaviti [8 2] — LSCC i TCC se u velikoj meri slažu, dok njihove nasleđene verzije izražavaju ekstreman konflikt. Naš cilj u ovom radu nije da rešimo ta pitanja, nego da pružimo metodologiju prema kojoj se ona mogu otkriti, u cilju pružanja pomoći budućim metričkim ispitivanjima. U nekim slučajevima, principi softverskog dizajna pokazuju koja je metrika najbolja. U drugim slučajevima, programer može odlučiti koja metrika najbolje odgovara njihovim potrebama.
Mi tvrdimo da ovaj pristup može značajno doprineti trenutnoj metričkoj debati. On pruža platformu na kojoj se metrike mogu animirati, a njihova područja saglasnosti i neslaganja dovedena su u jasan fokus. Budući rad u ovom polju podrazumeva izvođenje analiza pomoću šireg spektra ispitivanja, npr. korišćenje dve metrike, pokušaj da se izvrši prerađivanje tako što će se povećati njihovo neslaganje ili tako što će se metrika pogoršati što je više moguće pre prerađivanja koje će je ponovo poboljšati, kao i primena ovog pristupa na druge metrike - one metrike koje se najočiglednije spajaju. Drugo polje za buduća istraživanja jeste analiza prerađivanja koje uzrokuje konflikt između metrika. Ova analiza izvedena je ručno u ovom radu, ali pokušaj njenog automatizovanja predstavlja interesantan izazov za istraživanje.
9 References
[1] J. Al Dallal. Validating object-oriented class cohesion metrics mathematically. In SEPADS’10, USA, 2010.
[2] J. Al Dallal and L. Briand. A precise method-method interaction-based cohesion metric for object-oriented classes. ACM Transactions on Software Engineering and Methodology, 2010.
[3] J. Al-Dallal and L. C. Briand. An object-oriented high-level design-based class cohesion metric. Information & Software Technology, 52(12):1346–1361, 2010.
[4] E. B. Allen, T. M. Khoshgoftaar, and Y. Chen. Measuring coupling and cohesion of software modules: an information-theory approach. Proceedings Seventh International Software Metrics Symposium, (561):124–134, 2001.
[5] M. Alshayeb. Empirical investigation of refactoring effect on software quality. Information & Software Technology, 51(9):1319–1326, 2009.
[6] M. Alshayeb. Refactoring effect on cohesion metrics. In International Conference on Computing, Engineering and Information, 2009. ICC ’09, Apr. 2009.
[7] J. Bansiya, L. Etzkorn, C. Davis, and W. Li. A class cohesion metric for object-oriented designs. Journal of Object Oriented Programming, 11(08):47–52, 1999.
[8] J. M. Bieman and B.-K. Kang. Cohesion and reuse in an object-oriented system. In Symposium on Software reusability, Seattle, Washington, 1995.
[9] J. M. Bieman and L. M. Ott. Measuring functional cohesion. IEEE Transactions on Software Engineering, 20(8):644–657, Aug. 1994.
[10] C. Bonja and E. Kidanmariam. Metrics for class cohesion and similarity between methods. In Proceedings of the 44th annual Southeast regional conference, pages 91–95, Florida, 2006. ACM.
[11] L. Briand, K. E. Emam, and S. Morasca. On the application of measurement theory in software engineering. Empirical Software Engineering, 1:61–88, 1996.
[12] L. C. Briand, J. W. Daly, and J. Wüst. A unified framework for cohesion measurement in object-oriented systems. Empirical Software Engineering, 3(1):65–117, 1998.
[13] K. D. Cooper, P. J. Schielke, and D. Subramanian. Optimizing for reduced code space using genetic algorithms. In Proceedings of LCTES’99, volume 34.7 of ACM Sigplan Notices, pages 1–9, NY, May 5 1999.
[14] S. Counsell, S. Swift, and J. Crampton. The interpretation and utility of three cohesion metrics for object-oriented design. ACM Trans. Softw. Eng. Methodol., 15(2):123–149, 2006.
[15] S. Counsell, S. Swift, and A. Tucker. Object-oriented cohesion as a surrogate of software comprehension: an empirical study. In Proceedings of the Fifth IEEE International Workshop on Source Code Analysis and Manipulation, SCAM ’05, pages 161–172, Washington, DC, USA, 2005. IEEE Computer Society.
[16] D. Fatiregun, M. Harman, and R. Hierons. Evolving transformation sequences using genetic algorithms. In SCAM 04, pages 65–74, Los Alamitos, California, USA, Sept. 2004. IEEE Computer Society Press.
[17] D. Fatiregun, M. Harman, and R. Hierons. Search-based amorphous slicing. In WCRE 05, pages 3–12, Carnegie Mellon University, Pittsburgh, Pennsylvania, USA, Nov. 2005.
[18] N. E. Fenton. Software measurement: A necessary scientific basis. IEEE Transactions on Software Engineering, 20(3):199–206, 1994.
[19] N. E. Fenton and M. Neil. Software metrics: Roadmap. pages 357–370. ACM Press, 2000.
[20] N. E. Fenton and S. L. Pfleeger. Software metrics - a practical and rigorous approach (2. ed.). International Thomson, 1996.
[21] L. Fernández and R. P. na. A sensitive metric of class cohesion. Information Theories and Applications, 13(1):82–91, 2006.
[22] M. Fowler, K. Beck, J. Brant, W. Opdyke, and D. Roberts. Refactoring: Improving the Design of Existing Code. Addison-Wesley, 1999.
[23] E. Gamma, R. Helm, R. E. Johnson, and J. Vlissides. Design Patterns: Elements of Reusable Object-Oriented Software. Addison-Wesley, Reading, MA, 1995.
[24] T. Gutzmann et al. Recoder: a java metaprogramming framework, March 2010. http://sourceforge.net/projects/recoder.
[25] M. Harman and J. Clark. Metrics are fitness functions too. In Proc. International Symposium on METRICS, pages 58–69, USA, 2004. IEEE Computer Society.
[26] M. Harman, S. Danicic, B. Sivagurunathan, B. Jones, and Y. Sivagurunathan. Cohesion metrics. In 8th International Quality Week, pages Paper 3–T–2, pp 1–14, San Francisco, May 1995.
[27] M. Harman and L. Tratt. Pareto optimal search based refactoring at the design level. In Proceedings GECCO 2007, pages 1106–1113, July 2007.
[28] I. Hemati Moghadam and M. Ó Cinnéide. Automated refactoring using design differencing. In Proc. of European Conference on Software Maintenance and Reengineering, Szeged, Mar. 2012.
[29] A. Jensen and B. Cheng. On the use of genetic programming for automated refactoring and the introduction of design patterns. In Proceedings of GECCO. ACM, July 2010.
[30] P. Joshi and R. K. Joshi. Quality analysis of object oriented cohesion metrics. In QUATIC’10, pages 319–324. IEEE Computer Society, Oct. 2010.
[31] K. Kaur and H. Singh. Exploring design level class cohesion metrics. Journal of Software Engineering and Applications, 03(04):384–390, 2010.
[32] H. Kilic, E. Koc, and I. Cereci. Search-based parallel refactoring using population-based direct approaches. In Proceedings of the Third international Conference on Search Based Software Engineering, SSBSE’11, pages 271–272, 2011.
[33] A. Lakhotia. Rule–based approach to computing module cohesion. In Proceedings of the 15th Conference on Software Engineering (ICSE-15), pages 34–44, 1993.
[34] A. Nisbet. GAPS: A compiler framework for genetic algorithm (GA) optimised parallelisation. In P. M. A. Sloot, M. Bubak, and L. O. Hertzberger, editors, High-Performance Computing and Networking, International Conference and Exhibition, HPCN Europe 1998, Amsterdam, The Netherlands, April 21-23, 1998, Proceedings, volume LNCS 1401, pages 987–989. Springer, 1998.
[35] M. Ó Cinnéide, D. Boyle, and I. Hemati Moghadam. Automated refactoring for testability. In Proceedings of the International Conference on Software Testing, Verification and Validation Workshops (ICSTW 2011), Berlin, Mar. 2011.
[36] M. O’Keeffe and M. Ó Cinnéide. Search-based software maintenance. In CSMR’06, Mar. 2006.
[37] M. O’Keeffe and M. Ó Cinnéide. Search-based refactoring: an empirical study. J. Softw. Maint. Evol., 20(5):345–364, 2008.
[38] M. O’Keeffe and M. Ó Cinnéide. Search-based refactoring for software maintenance. J. Syst. Softw., 81(4):502–516, 2008.
[39] M. O’Keeffe and M. Ó Cinnéide. A stochastic approach to automated design improvement. In PPPJ’03, pages 59–62, Kilkenny, June 2003.
[40] F. E. B. Otero, C. G. Johnson, A. A. Freitas, , and S. J. Thompson. Refactoring in automatically generated programs. Search Based Software Engineering, International Symposium on, 0, 2010.
[41] H. Sahraoui, R. Godin, and T. Miceli. Can metrics help to bridge the gap between the improvement of OO design quality and its automation? In ICSM’00, pages 154–162, Oct. 2000.
[42] O. Seng, J. Stammel, and D. Burkhart. Search-based determination of refactorings for improving the class structure of object-oriented systems. In GECCO ’06, Seattle, Washington, USA, 8-12 July 2006. ACM.
[43] M. J. Shepperd. Foundations of software measurement. Prentice Hall, 1995.
[44] G. Succi, W. Pedrycz, S. Djokic, P. Zuliani, and B. Russo. An empirical exploration of the distributions of the chidamber and kemerer object-oriented metrics suite. Empirical Software Engineering, 10(1):81–104, 2005.
[45] E. J. Weyuker. Evaluating software complexity measures. IEEE Transactions on Software Engineering, 14(9):1357–1365, Sept. 1988.
[46] K. P. Williams. Evolutionary Algorithms for Automatic Parallelization. PhD thesis, University of Reading, UK, Sept. 1998.