A few of you might remember a blog post of mine from 2011 titled Parsing: The Solved Problem That Isn’t. My hope with parsing has always been that I can take an off-the-shelf approach and use it without having to understand all the details. In that particular post, I was looking at parsing from the angle of language composition: is it possible to glue together two programming language grammars and parse the result? To cut a long story short, my conclusion was none of the current parsing approaches work well for language composition. I was nervous about going public, because I felt sure that I must have missed something obvious in what is a diffuse area (publications are scattered across different conferences, journals, and over a long period of time). To my relief, a number of parsing experts have read, or heard me talk about, the technical facts from that post without barring me from the parsing community1.
When I wrote the original blog post, I did not know if a good solution to the problem I was considering could exist. I ended by wondering if SDE (Syntax Directed Editing) might be the solution. What I’ve discovered is that SDE is a wonderful way of guessing someone’s age: those under 40 or so have rarely heard of SDE; and those above 452 tend to either convulse in fits of laughter when it’s mentioned, become very afraid, or assume I’m an idiot. In other words, those who know of SDE have a strong reaction to it (which, almost invariably, is against SDE). This blog post first gives an overview of SDE before describing a new approach to editing composed programs that we have developed.
Syntax directed editing
Imagine I want to execute a program which adds 2 and 3 times x
together. I fire up my trusty text editor, type 2 + 3 * x in, and pass
it to a compiler. The compiler first parses the text and creates a parse tree
from it, in this case plus(int(2), mul(int(3), var(x)), and then uses that tree
to do the rest of the compilation process. In a sense, when
programming in a text editor I think in trees; mentally flatten that tree
structure into sequences of ASCII characters that I can type into the text
editor; and then have the parser recreate the tree structure I had in my head
when I wrote the program. The problem with this process is not, as you might be
thinking, efficiency—even naive parsing algorithms tend to run fast enough on
modern machines. Rather it is that some apparently reasonable
programs fail to parse, and the cause of the errors can be obscure, particularly to
novice programmers.
In the early 80s, a number of researchers developed SDE tools as a solution to the
problem of frustrated and demotivated novices. Instead of allowing people to
type in arbitrary text and parsing it later, SDE tools work continuously on trees.
SDE tools have the grammar of the language being edited built in, which means
they know which trees are syntactically valid. Rather than typing in 2 + 3 * x, one first instructs the SDE tool to create a plus node. A box with a
+ character appears on screen with two empty boxes to the left and
right. One then clicks in the left hand box, types 2, before clicking in
the right hand box and typing *. Two more boxes appear on screen into which
one enters 3 and x. There is therefore no need for
parsing to ever occur: one can directly input the tree in one’s head into the SDE tool,
rather than indirectly specifying it via a sequence of ASCII characters.
The advantage of SDE is that it guides users in creating correct programs.
Indeed, SDE tools actively prevent incorrect programs from being created: at all
points the tree is syntactically correct, albeit some holes may be temporarily
unfilled. However, this advantage comes at a severe cost: to be frank, SDE tools
are generally annoying to use. Novices, like small children, will tolerate nearly
anything you throw at them, because they are unaware of better
alternatives. When seasoned programmers were asked to use SDE tools, they
revolted against the huge decline in their productivity. SDE tools not only make
inputting new programs somewhat annoying, but they completely change the way
existing programs are edited. Two examples will hopefully give you an idea of
why. First, programmers often get half way through an edit in one part of a file
(e.g. starting an assignment expression) and realise they need to define
something else earlier in a file. They therefore break off from the initial
edit, often leaving the program in a syntactically invalid state, and make
textual edits elsewhere, before returning to the initial edit. SDE tools tend to
forbid such workflows since they need to keep the program in a syntactically
valid state3. Second, when editing text, it is often
convenient to forget the tree structure of the program being edited, and treat
it as a simple sequence of ASCII characters. If you ever done something like selecting
2 + 3 from the expression 2 + 3 * x, you have done just this. SDE tools force edits to be
relative to a tree. For example, code selections invariably have to be of a
whole sub-tree: one can select 2, or +, or
3, or 3 * x (etc.) but not 2 + 3. If this this
seems like a minor restriction, you should try using such a tool: I don’t think
there is a programmer on this earth who will not find the changes required to
use such tools hugely detrimental to productivity.
SDE tools thus quickly disappeared from view and within a few years it was almost as if they had never existed. The world would not have been much worse off for this, except for the fact that SDE and language composition are a perfect match. Whereas composing traditional grammars or parsers always involves trade-offs of expressivity or reliability, SDE imposes no such compromise. Since SDE tools are always in control of the languages they are editing, they can allow arbitrary languages to be composed in powerful ways.
I was certainly not the first person to note the potential of SDE for
language composition. JetBrains MPS tool is a relatively
recent SDE tool which allows composition of powerful editors. To the best of my
knowledge, it is the most pleasant SDE tool ever developed. In particular, when
entering new text, MPS feels tantalisingly close to a normal text editor. One
really can type in 2 + 3 * x as in a normal text editor and have the
correct tree created without requiring unusual interactions with the user
interface. MPS applies small
tree-rewritings as you type, so if you follow 2 with
+, the 2 node is shuffled in the tree to make it the
left hand child of the +, and the cursor is placed in an empty box to the
right hand side of the +. The author of the language being
edited by MPS has to enable such transformations, and while this
is no small effort, it is a cost that need be paid only once. However, whilst MPS does a good job of
hiding its SDE heritage when typing in new text, editing old text has many of
the same restrictions as traditional SDE tools. As far as I can tell, MPS has gradually
special-cased some common operations to work normally (i.e. as in a
text editor), but many common operations have surprising effects. In some cases, edits which
are trivial in a traditional editor require special key-presses and actions
in MPS to extract and reorder the tree.
MPS is a striking achievement in SDE tools. It lowers SDE to the point that some programmers can be forced, with some encouragement, to use it. Some of the compositions using MPS are truly stunning, and have pushed the envelope far further than anyone has ever managed before. But, if I’m being honest, I wouldn’t want to edit a program in MPS, using its current editor, and nor do I think programmers will take to it voluntarily: it makes too many simple things complicated.
A new solution
Simplifying a little, it seemed to us that MPS had made as good a stab as anyone is likely to manage at moving an SDE tool in the direction of a normal text editor; we wondered if it might be possible to move a normal text editor in the direction of SDE. In other words, we hoped to make an editor with all the tree goodness of SDE tools, but which would feel like a normal text editor. So, two years ago, in the Software Development Team at King’s College London, we set out to see if such a tool could exist. I am happy to say that we now believe it can, and we (by which I mostly mean Lukas Diekmann) have created a prototype editor Eco based on the principles we have developed. In essence, we have taken a pre-existing incremental parsing algorithm and extended it such that one can arbitrarily insert language boxes at any point in a file. Language boxes allow users to use different language’s syntaxes within a single file. This simple technique gives us huge power. Before describing it in more detail, it’s easiest to imagine what using Eco feels like.
An example
Imagine we have three modular language definitions: HTML, Python, and SQL. For
each we have, at a minimum, a grammar. These modular languages can be composed
in arbitrary ways, but let’s choose some specific rules to make a composed
language called HTML+Python+SQL: the outer language box must be
HTML; in the outer HTML language box, Python language boxes can be inserted
wherever HTML elements are valid (i.e. not inside HTML tags); SQL language boxes
can be inserted anywhere a Python statement is valid; and HTML language boxes
can be inserted anywhere a Python statement is valid (but one can not nest
Python inside such an inner HTML language box). Each language uses our
incremental parser-based editor. An example of using Eco can be seen
in Figure 1.
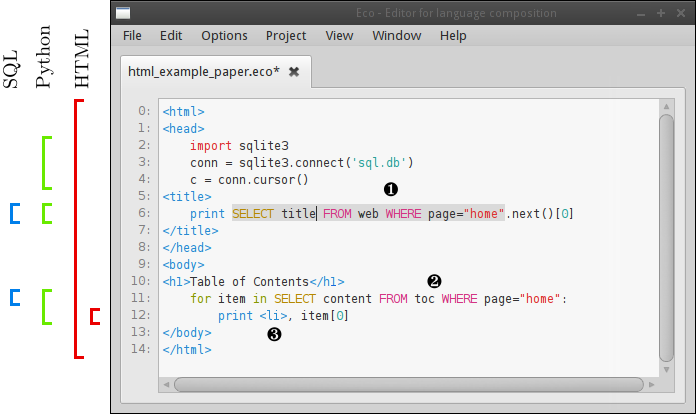
Figure 1: Editing a composed program. An outer HTML document contains several Python language boxes. Some of the Python language boxes themselves contain SQL language boxes. Some specific features are as follows. ❶ A highlighted (SQL) language box (highlighted because the cursor is in it). ❷ An unhighlighted (SQL) language box (by default Eco only highlights the language box the cursor is in, though users can choose to highlight all boxes). ❸ An (inner) HTML language box nested inside Python.
From the user’s perspective, after loading Eco, they can create a new file of type HTML+Python+SQL. After the blank page appears, they can start typing HTML exactly as they
would in any other editor, adding, altering, removing, or copying and pasting text without
restriction. The HTML is continually parsed by the outer language
box’s incremental parser and a parse tree constructed and updated appropriately
within the language box. Syntax errors are highlighted as the user types with red squiggles.
The HTML grammar is a standard BNF grammar which specifies where
Python+SQL language boxes are syntactically valid by referencing a
separate, modular Python grammar. When the user wishes to insert Python code,
they press Ctrl+L, which opens a menu of available languages (see Figure 2); they
then select Python+SQL from the languages listed and in so doing insert a Python
language box into the HTML they had been typing. The Python+SQL language box can
appear at any point in the text; however, until it is put into a place consistent
with the HTML grammar’s reference to the Python+SQL grammar, the language box will
be highlighted as a syntax error. Note that this does not affect the user’s
ability to edit the text inside or outside the box, and the editing experience
retains the feel of a normal text editor. As Figure 3 shows, Eco
happily tolerates syntactic errors — including language boxes in positions
which are syntactically invalid — in multiple places.
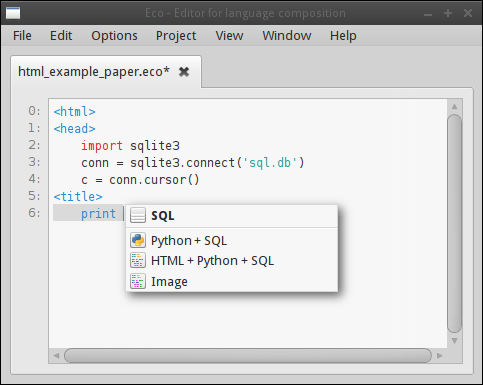
Figure 2: Inserting a language box opens up a menu of the languages that Eco knows about. Languages which Eco can be sure are valid in the current context are highlighted in bold to help guide the user.
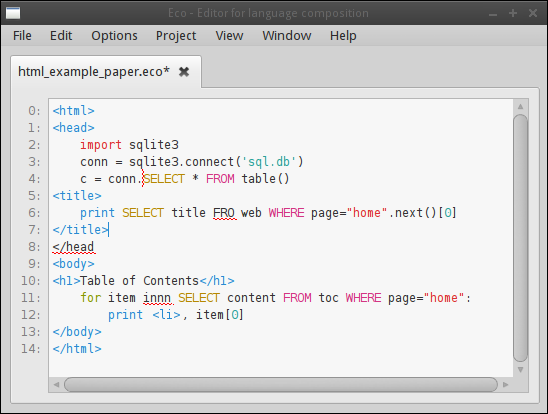
Figure 3: Editing a file with multiple syntax errors. Lines 6, 8 and 11 contain syntax errors in the traditional sense, and are indicated with horizontal red squiggles. A different kind of syntax error has occurred on line 4: the SQL language box is invalid in its current position (indicated by a vertical squiggle).
Typing inside the Python+SQL language box makes it visibly grow on screen to
encompass its contents. Language boxes can be thought of
as being similar to the quoting mechanism in traditional text-based approaches
which use brackets such as [|...|]; unlike text-based brackets,
language boxes can never conflict with the text contained within them. Users can
leave a language box by clicking outside it, using the cursor keys, or pressing
Ctrl+Shift+L. Within the parse tree, the
language box is represented by a token whose type is Python+SQL and whose
value is irrelevant to the incremental parser. As this may suggest, conceptually the top-level
language of the file (HTML in this case) is a language box itself. Each language
box has its own editor, which in this example means each has an incremental
parser.

Figure 4: An elided example of an SQL language box nested within an outer Python language box. From the perspective of the outer incremental parser, the tree stops at the SQL token. However, we can clearly see in the above figure that the SQL language box has its own parse tree.
Assuming that there are no syntax errors, at the end of the editing process, the user will be left with a parse tree with multiple nested language boxes inside it as in Figure 4. Put another way, the user will have entered a composed program with no restrictions on where language boxes can be placed; with no requirement to pick a bracketing mechanism which may conflict with nested languages; with no potential for ambiguity; and without sacrificing the ability to edit arbitrary portions of text (even those which happen to span multiple branches of a parse tree, or even those which span different language boxes). In short, Eco feels almost exactly like a normal text editor with the only minor difference being when one enters or exits a language box.
How it works
Language boxes are an embarrassingly simple concept, based on a very simple observation. Context free parsing orders tokens into a tree based solely on the types of tokens: the value is not looked at (doing so would make the parser context sensitive, which is generally undesirable). When the user presses Ctrl+L and selects language L, Eco simply creates a token in the parse tree of type L. From the perspective of each tree, language boxes are normal tokens; the fact that they have sub-trees as values is of no consequence to the parser.
Consequences
Since, in general, one cannot guarantee to be able to parse as normal text the programs that Eco can write, Eco’s native save format is as a tree4. This does mean that one loses the traditional file-based notion of most programming languages. Fortunately, other communities such as Smalltalk have long since worked out how to deal with important day-to-day functionality like version control when one moves away from greppable, diffable, files. We have not yet incorporated any such work, but it seems unlikely to be a hugely difficult task to do so.
Some thoughts
We think that Eco is not only the first in a new class of editor, but the first editor which makes editing composed programs painless. Put another way, I wouldn’t mind using an Eco-like tool to edit composed programs, and I am extremely fussy about my text editor. The fact that I say Eco-like is not accidental. Eco is a prototype tool, with all that entails: it is hugely incomplete (e.g. we currently have little or no undo functionality, depending on how you view things), buggy, and sometimes unexpectedly slow (though not because of the incremental parser, which is astonishingly fast). What we have learnt in building it, however, is more than sufficient to see how the ideas would scale up to an industrially ready tool. Will such a tool ever appear? I don’t know. However, unlike when I wrote my original blog post, I can now state with some confidence that a good solution is possible and practical.
If you’re interested in finding out more about Eco, you can read the (academic) SLE paper this blog post is partly based on, or download Eco yourself5. The paper explains a number of Eco’s additional features—it has a few tricks up its sleeves that you might not expect from just reading this blog.
It is also important to realise that Eco is not magic: it is a tool to
make editing composed programs
practical. It is still necessary to specify what the composed syntax
should mean (i.e. to give it semantics), assuming we want to do something with
the result. In the case of the HTML+Python+SQL composition, composed programs
can be exported to a Python file and then executed. Outer HTML fragments are
translated to print statements; SQL language boxes to SQL API calls (with their
database connection being to whatever variable a call to
sqlite3.connect was assigned to); and inner HTML fragments to
strings. We can thus export files from our composition and run them as normal
Python programs. There are many other possible, and reasonable, ways to export a
program from Eco, and one can imagine a single composition having multiple
exporters. If you want to see how Eco fits into the wider language
composition landscape, this video of a recent talk shows some of the directions we’re pushing ahead on.
Acknowledgements: This work was generously funded by Oracle Labs without whom there would be no Eco. Lukas Diekmann has been the driving force behind Eco. Edd Barrett and Carl Friedrich Bolz gave insightful comments on a draft of this blog post.
Footnotes
[1] Though some of them quite reasonably disagree with me as to whether some of the limitations or trade-offs I mentioned really rule out some approaches from language composition.
[1] Though some of them quite reasonably disagree with me as to whether some of the limitations or trade-offs I mentioned really rule out some approaches from language composition.
I’m not sure if my sample size of 40-45 year olds is insufficient, or whether they really are the inbetween generation when it comes to SDE. Fortunately, I will sleep soundly enough without knowing the answer to this particular question.
I’m not sure if my sample size of 40-45 year olds is insufficient, or whether they really are the inbetween generation when it comes to SDE. Fortunately, I will sleep soundly enough without knowing the answer to this particular question.
I’m told that some of the original SDE tools were more flexible than this suggests, but these seem to be the exception, and not the rule. It’s unclear to me exactly how flexible such tools were in this regard. Alas, the software involved has either disappeared or requires impossibly ancient hardware and software to run.
I’m told that some of the original SDE tools were more flexible than this suggests, but these seem to be the exception, and not the rule. It’s unclear to me exactly how flexible such tools were in this regard. Alas, the software involved has either disappeared or requires impossibly ancient hardware and software to run.
It currently happens to be gziped JSON, which is an incidental detail, rather than an attempt to appeal to old farts like me (with gzip) as well as the (JSON-loving) kids.
It currently happens to be gziped JSON, which is an incidental detail, rather than an attempt to appeal to old farts like me (with gzip) as well as the (JSON-loving) kids.
Depending on when you read this, you may wish to check out the git repository, in order to have the latest fixes included.
Depending on when you read this, you may wish to check out the git repository, in order to have the latest fixes included.