Amongst the many consequences of COVID-19 has been the suspension of in-person talks: suddenly, people like me have had to think about how to produce prerecorded videos. In this article I’m going to explain what I’ve come to understand about video recording and the “automatic video editing” technique I’ve used for videos such as Virtual Machine Warmup Blows Hot and Cold.
To give you an idea of how unfamiliar I was with video production, 12 months ago I not only had no experience of creating videos but I hadn’t even watched enough videos to form an opinion of what was possible or desirable. However, within a couple of hours of attending my first online conference in June 2020, the challenges of video production had become clear to me. To be blunt, most of the videos I was watching were worse than the equivalent live talk: they were mostly bullet point laden PowerPoint slides with poor quality audio. I’ve long been of the opinion that bullet point presentations are unengaging, as they’re designed for the speaker’s benefit, not the audience’s. However, they become even less engaging when there’s no person to look at and all you can hear is a disembodied, poorly amplified, and fuzzy-sounding mumble. Fortunately for me, I saw a talk by Sam Ainsworth that showed me that a different, rather more engaging, type of talk was possible.
Realising that I’d need to produce videos of my own at some point, I immediately1 started looking into how one might go about recording videos. Unfortunately, it soon became obvious that common video production tools such as OBS hadn’t been ported to OpenBSD2. Undeterred, the following day, I experimented with using FFmpeg to record and mix videos. I’ll go into more detail about FFmpeg later, but at this point it’s enough to know that FFmpeg is a powerful command-line tool that can record and edit videos.
After a while, I’d realised that what I wanted to produce are “screencasts with a talking head” videos, which superimpose a shot of a human head onto a capture of a desktop computer’s screen. I’d soon grappled with FFmpeg enough that I could record my camera, microphone, and X11 screen (i.e. my computer display) into separate video files. Then I started trying to edit the resulting files into a half-decent recording and ran into what I’ve since realised is a truism: video editing is hard.
Current approaches to video editing
I’ve done quite a lot of audio recording in my time, and editing it is easy: audio is easily visualised as a wave form, and searching for silences, in particular, is trivial. Selecting the appropriate parts to delete is a simple matter of a couple of mouse clicks and pressing “delete”. For a 15 minute podcast, I probably record about 40 minutes of audio and then spend about 30 minutes editing that down to the final 15 minutes. It might surprise you that editing takes less time than there are minutes of recorded audio, but many unwanted parts (e.g. long periods of silence where I’m glugging water) are so visually obvious that I don’t even need to listen to them.
It is one of life’s odder ironies that it’s impossible to sensibly visualise a video consisting of more than a handful of frames. Finding the right parts to delete is a slow job that involves lots of hunting around and replaying — sometimes the audio part of the video can help speed this up, but silence is not a guarantee that nothing interesting is happening on screen.
The sheer size of video files makes the editing process even more painful — manipulating videos taxes even the most powerful of computers. Saving out a 25 minute video on my computer using a software encoder3 can easily take 10 minutes, utilising all 4 cores to the maximum while doing so. Experimentation is constrained by long turn-around times.
Two other things exacerbate the problem. First, there’s a lot more that can go wrong when recording a video, so to get the same quality as the equivalent audio-only recording, I typically have to record quite a lot more footage, meaning there’s more to edit. Second, video gives one more options, for example, I might want some scenes in the final video to have just the screen, some to be of just me talking, and some to be a mix of the two. Extra options mean extra complexity, which means extra editing time.
It is thus probably unsurprising that audio and video editing tools vary substantially in difficulty. I must admit that I find Audacity a frustrating tool, as each new version finds new ways of crashing on me, and some of its processing tools are underwhelming4. However, I think that even someone unfamiliar with audio editing can get to grips with Audacity in a few minutes. More sophisticated multi-track editors like Ardour (a wonderful, and underappreciated, program in my opinion) are harder to learn, but they pale in comparison to video editors. I’ve mostly used Shotcut because it’s the least hard to use tool I’ve found of that ilk, but it’s still awkward to learn and use, because video editing is fundamentally challenging: to do anything even moderately complex, I have to trawl around various online forums and YouTube videos to find out the sequence of steps to follow.
Automatic video editing
Just at the point that I was starting to despair at how much of my life I might have to dedicate to editing videos, I stumbled across a wonderful idea from Vivek Haldar, who showed that it’s possible to automatically edit videos. In essence, Vivek’s approach is to have a final video comprised of what I’ll call multiple scenes, where the scenes are specified by placing markers in the video that mean “I’m happy with the last scene” and “rewind to the beginning of the last scene and let me try recording it again” (enabling what are called retakes). The markers are embedded in a very literal sense — they turn most of the screen capture red or green in the recorded video (see e.g. 3:45 in Vivek’s video). A Python script then analyses each frame in the video for those markers and extracts the “good” portions to create a final video suitable for uploading elsewhere.
In my opinion, Vivek’s idea is beautifully simple, as it automates away the torturous job of extracting the portions of a recording that you want to keep. I quickly experimented with his idea in my FFmpeg setup, but found that the red and green flashes reflected on my face, making me look like alternately satanic or queasy5. Vivek solves this by also automatically editing out silences, but, as we’ll see later, I want greater control over transitions. I also tried delaying the recording either side of the pauses, but found that made it difficult to time transitions appropriately. I was tempted to give up at this point, but Vivek’s idea was just too appealing, so I wondered if I could achieve the same effect without embedding colours in the video.
An overview of Aeschylus
What I eventually came up with is Aeschylus (a sort-of acronym for “Auto-Editing ScreenCasts”). Aeschylus is a proof of concept for automatic video editing — it is not, to put it mildly, very polished. When I started writing it I had no idea of what I wanted, no idea of what was possible, and no idea of how to go about doing the things that I didn’t know I wanted. That lack of clarity is reflected in its mish-mash of shell script, Python, and generated Makefiles. That said, after 6 months of using Aeschylus, I think I’ve gained enough experience to say with confidence that automatic video editing works, that other people might find Aeschylus’s style of automatic video editing useful, and that more robust video production systems should be able to easily integrate something equivalent.
Before I go any further, it’s worth being clear as to what Aeschylus is and isn’t suited to. It:
-
targets a simple style of videos: screencasts with a talking head.
-
produces videos suitable for uploading to sites like YouTube: it is not useful for live streaming.
-
intentionally doesn’t edit “on the fly”. All the constituent parts (e.g. recordings of the camera and screen) are kept separate and can be edited separately later if problems are found.
-
expects you to record your videos in one location in one sitting (perhaps one could relax this requirement somewhat, but at some point you’d end up back at the complexity of “traditional” video editing).
-
requires you to be at a computer during recording or, at least, having a means of telling the recording software when you want to set a marker.
These constraints are acceptable for some purposes (e.g. lecturing or teaching), but not others. In particular, if you have any artistic intentions for your videos, this is not going to be the technique for you.
What you get in return for accepting these constraints is a minimal-effort
means of producing decent-ish looking videos. In my case,
when I’m ready to record a video, I run Aeschylus, press Ctrl+F2
when I’m ready to start the “good” footage, talk for as long as I need to, and
press Ctrl+F3 when I’m finished. Aeschylus then switches from
“recording” to “editing” mode which involves lengthy, fully automated, video
processing. A little while later, I’m presented with a .nut6 file suitable for uploading to YouTube.
A couple of examples of publicly accessible videos that I’ve produced with Aeschylus are Don’t Panic! Better, Fewer, Syntax Errors for LR Parsers and Virtual Machine Warmup Blows Hot and Cold. While no-one is going to confuse either video with a professional documentary, I think their quality is adequate enough that it’s not distracting. Both videos required precisely zero editing after recording.
Markers
The main difference between Aeshchylus and Vivek’s system is that Aeschylus
stores markers in a separate file to the video, recording the wall-clock time that
the marker was added to the file. For example, when I press
Ctrl+F1 a safepoint marker is added, when I press
Ctrl+F2 a rewind marker is added, and when I press
Ctrl+F3 a fastforward marker is added. After
recording is complete, the markers file looks something like:
1615910625.813433 rewind 1615910640.256888 rewind 1615910653.923218 safepoint 1615910669.182979 rewind 1615910680.459997 fastforward
The long numbers are times in seconds since the Unix epoch, allowing us to tell when those markers were recorded (in this case, approximately 2021-03-16 16:03) down to a fraction of a second. One obvious concern with this problem is how to synchronise the markers with the recording: I’ll talk about that in detail a bit later.
The three marker types used above mean the following:
rewind: retake the current scene, rewinding to the previoussafepointor, if there are no previoussafepoints, the start of the recording.safepoint: commit the previous scene.fastforward: ignore the recording from this point until the nextsafepointor, if there are no subsequentsafepoints, until the end of the recording.
Those three marker types might not feel like much, but they’re surprisingly
powerful. rewind can be used to denote “start video extraction
from this point” and fastforward can be used to denote “stop video
extraction at this point”. It’s normal to have multiple adjacent
rewinds since they ignore any preceding marker that isn’t a
safepoint. Aeschylus also has an undo marker which
deletes the preceding marker, if there is one, but I’ve never used it in
practise.
Thus, for the example markers above, Aeschylus will trim the start (from the
very beginning of the recording up to the second rewind marker),
edit out the retake between the safepoint and the second
rewind, and then trim the end (the fastforward).
At this point it’s probably easiest to see examples. I recorded a simple “demo” video with a few example markers and first of all removed those markers so that you can see the “before” footage. This includes the inevitable wonky first second of camera footage when using FFmpeg on OpenBSD but, more usefully, shows the FFmpeg recording process running in the centre and highlights the markers that are set in the bottom left:
If I put the markers back in and rerun Aeschylus it then produces an automatically edited video. If you’re not quite sure how this works, you might find it useful to compare the frame count in the FFmpeg process in the video above and below. The “after” video thus looks as follows:
Hopefully that gives you a good idea of what automatic video editing does.
The minimum practical sequence of markers to produce a video is simply
rewind and fastforward. In practise, I tend to start
with multiple rewinds (introductions are important, and it takes
me a little while to get into the swing of things),
with subsequent safepoints followed by zero or more
rewinds, and one final fastforward.
One take versus multiple takes
Aeschylus makes it easy to retake (i.e. rerecord) a scene as often as you can stomach, without incurring any extra editing time. This leads to an inevitable debate about the virtues of “authentic” and “perfect” recordings7. On one side of the argument, people assert that “authentic” recordings emulate the wonders of a live talk while “perfect” recordings feel stiff and robotic.
I think this overlooks the fact that truly good live talks are hard to give and thus rare. Part of that is inherent — most people, including me, are not natural public speakers, so we tend to fumble over our words, pause randomly, or repeat ourselves unnecessarily. Part, annoyingly, is because many speakers do not adequately practise: at the most extreme are those speakers to whom each slide in their talk comes as a visible surprise. While some amazing live speakers can probably create wonderful videos in a single take, the rest of us should probably expect to retake parts of a talk if we value, and want to use efficiently, our viewer’s time.
As this suggests, I have little truck with the idea of an “authentic” talk but I don’t want to fall into the trap of trying to create a perfect talk. If nothing else, I probably wouldn’t succeed in doing so, but would exhaust myself in the attempt. Fortunately, I’ve found that when recording videos, one can easily explore the middle group between authentic and perfect, and automatic video editing makes doing so even easier. Just as with live talks, I’ve ended up producing two classes of video.
First is what I’ll call “lecturing”, by which I mean delivering lengthy quantities of material in a relatively short period of time (e.g. lecturing undergraduate students might involve 20+ hours of lectures over 10 weeks). When lecturing in-person, I can’t realistically practise everything I’m going to say in advance, so I end up pausing, repeating, and fumbling a reasonable amount. Similarly, I need to produce enough lecture-quality videos that I need to tolerate a certain level of inefficiency and imperfection in my delivery if I want to record them in reasonable time. When using Aeschylus, I have settled into a consistent pattern where I have a record:keep ratio of about 2:1 (i.e. for every 10 minutes of material I record I keep 5 minutes). More interestingly, these videos have a live-length:video-length ratio of about 2:1 (i.e. for every 10 minutes I would have spoken in real life, the video covers the same ground in 5 minutes). It took me a little while to realise that, with automatic video editing, I’m spending the same time recording videos as I spent delivering them in-person — but viewers only have to spend half as long watching to get the same – in fact, better! – results. Part of that is the reduction in talking inefficiencies, but part of it is because I no longer have to repeat myself as often: if students miss something, they can rewind to focus on just that part. This, in my opinion, is a significant improvement relative to live lectures.
Second is what I’ll call “research talks”, by which I mean one-off, shorter talks, generally on a highly technical topic. When giving these in-person I generally have to practise them several times in order that they’re somewhat accurate and complete. What happens if we try and maintain these standards for video recordings? For the two cases I’ve done so far (Don’t Panic! Better, Fewer, Syntax Errors for LR Parsers and Virtual Machine Warmup Blows Hot and Cold) I’ve had a record:keep ratio of about 5:1 to 6:1 (i.e. for every 10-12 minutes of material I record, I keep 2 minutes). I estimate the live-length:video-length coverage ratio to be about 1.5:1 (i.e. for every 10 minutes I would have spoken in real life, the video covers the same ground in about 7 minutes). However, the recorded videos are more accurate and complete than the equivalent in-person talks, so that ratio perhaps undersells things.
There is one final factor that’s worth considering in this context: how long should a scene in a video be? It would be possible to put together a perfect recording consisting of scenes that last a few seconds each, but when transitions are too frequent, the final video feels inhuman and unsettling. In general, I aim for scenes to average around 30-90 seconds. 30 second scenes seem to be above the “inhumanly frequent transition” threshold, and 90 second scenes mean that, when I inevitably fumble my words, I don’t have to repeat too much content. Put another way, the longer a scene is, the more opportunities I’m giving myself to make a bad enough mistake that I feel forced to do a retake.
In summary, whether I’m producing lecturing or research quality videos, my personal aim is not to produce perfect videos. Instead, I deliberately aim for something at least a little short of perfect: I retake a scene when I think I’ve paused or fumbled in a grating manner, but I’m willing to accept minor pauses and fumbling in. While I’m not saying I’ve got the balance right, I hope this leaves a “human” element to the videos, while also wasting very little of the viewer’s time.
Scene transitions and layouts
Aeschylus originally supported only one scene layout: screen capture with a
shrunken version of me in the bottom right corner (e.g. Don’t Panic! Better, Fewer, Syntax Errors for LR Parsers). Because I appear in the same position during the whole video, I soon realised that
transitions between scenes can be extremely jarring if I’ve moved too much
either side of the transition8. Fortunately there is
a simple solution: at each safepoint and rewind I sit
upright, look at the same part of my camera, and try to strike a neutral tone
with my face. The resulting transitions are still visible, but they’re much
less jarring.
While this simple scene layout is fine for short videos, it can feel rather boring for longer videos. To solve that problem, I realised that I needed to add support for additional scene layouts: just the screen capture; and a full scale version of my made-for-radio face. You can see all three scene layouts in action in Virtual Machine Warmup Blows Hot and Cold.
Although I cannot deny a certain vanity behind the full-scale face scene layout, I think the different layouts make the resulting videos a bit more engaging. To my surprise, despite being much more obvious, transitions between different scene layouts are much less jarring than transitions within the same scene layout. I’m not sure if that’s because I’ve become inured to that type of transition from over-consumption of television and film, or whether it’s something more fundamental, but it doesn’t really matter either way.
To switch scene layout, Aeschylus has additional marker types (e.g.
camera0_scene, screen0_scene, and so on). There is an
interesting interaction between setting a scene layout and rewind.
My first implementation made Aeschylus “remember” which scene layout was active at a safepoint,
reverting to that if a rewind was encountered. However, that made
it impossible to cleanly change scene layout as it always happened during
a “live” scene. Now, rewind does nothing to change scene layout.
Fortunately, this is easy to use in practise. After a safepoint, I
set a new scene layout marker if I need one, then set a rewind marker, and
carry on. I don’t ever try to change scene layouts in the middle of a scene.
Occasionally I forget to change scene layouts at safepoints or
change to the wrong scene layout. Fortunately, because Aeschylus (intentionally)
only edits after recording has completed, it’s easy to edit the
markers file to add or remove the necessary scene change marker
and regenerate the video.
A final challenge with scene transitions is getting an appropriate gap
between the final word in the last scene and the first word in the next
scene. Too large a gap feels a bit weird; too small a gap can be incredibly
jarring. My solution is simple: I set a safepoint just slightly
before the point that I would start speaking again; and as soon as I set a
rewind, I breathe in to start speaking. In other words, the “gap”
is unevenly distributed, with most of it being at the end of a scene9.
FFmpeg
FFmpeg is often described as the Swiss army knife of video tools, which is unfair: compared to FFmpeg, Swiss army knives have a miserly number of tools. Now that I know what to look for, I suspect that nearly every video we watch digitally has passed through FFmpeg at least once. Aeschylus uses FFmpeg for recording (which is fairly easy) and editing (which turns out to be rather harder).
The sheer variety of tasks that FFmpeg can accomplish means that it would be unreasonable to expect it to be an easy tool to use. However, FFmpeg is even more difficult to use than one might expect, for three reasons. First, it is an old tool, so inevitably there are layers of cruft, and unfortunate design decisions, that can’t be removed or changed without breaking backwards compatibility. Second, although nearly every feature is documented, virtually no feature is documented in a useful way. A common idiom is to say “Feature X does X”, with no real explanation of what X does, or any indication of the implications of using that feature. Third, FFmpeg only rarely complains that data can’t be processed: in general, if it’s not in quite the format the next stage in the pipeline requires, it will coerce it to make it suitable10, silently choosing values for any options you didn’t think to specify. If, as is common, the output doesn’t play as you hoped, you have to work out what options are applicable to to your input and output and try adjusting them. I have often had to dig into FFmpeg’s source code to find out what’s going on, and sometimes I’ve had to resort to sheer guesswork11.
However, in case this sounds like whinging, I want to be clear: I really like FFmpeg. Once you’ve got your head around its major concepts – in particular, its powerful filters – you can automate an astonishing number of tasks. Here’s an example of the sort of pipeline that Aeschylus uses:
ffmpeg -hide_banner \ -i camera0.nut \ -filter_complex " \ [0:a]pan=mono|c0=c0+c1[a]; \ [0:v] \ fps=fps=24, \ crop=1400:1045:330:0, \ vaguedenoiser, \ chromakey=3e5b0b:0.04:0.02, \ despill=type=green:mix=0.5:expand=0.3:brightness=0:green=-1:blue=0 \ [camera0]; \ color=c=0x595959:r=24:s=1920x1080 \ [screen0]; \ [screen0][camera0] \ overlay=shortest=1:x=W-w+0:y=H-h+1 \ [v]" \ -map "[a]" -map "[v]" \ -f nut -c:v libx264 -crf 0 -preset ultrafast -c:a flac out.nut
I won’t go into all the details, but a few clues can go a long way to making
sense of FFmpeg. This command takes as input the file camera0.nut,
processes it, and writes the output to out.nut,
encoding the video as H.264 and the audio as flac.
The -filter_complex option allows you to access FFmpeg’s full
range of features via a filter expression language. Each
stage in the pipeline takes in zero or more streams and produces one or more
streams as output, with the syntax
[in_1][in_n]filter=opt_1=val_1:opt_n=val_n[out_1][out_n] (note
that stream names can be, and often are, reused).
The input file is split into two: the audio stream becomes [0:a]
and the video stream [0:v]. The -map arguments
specify which streams end up in the output file (in this case the
[a] and [v] streams).
In this example, the filter pipeline
converts the stereo audio to mono (pan=...), crops the
image (crop=...), reduces camera noise
(vaguedenoiser12), removes the green screen
(chromakey=...) and any reflection from the green screen
(despill=...), generates a 1080p grey image (color=...),
and places the camera footage over that grey image (overlay=...).
Here’s a before and after:


As I hope this suggests, FFmpeg is incredibly powerful, including a wide array of image and audio processing possibilities.
There are, of course, some quirks. For quite a
while Aeschylus produced output videos in one go, but as the processing became
more complex, I discovered that FFmpeg sometimes wants to buffer input before
running a filter: from memory, the overlay filter is a surprising culprit
(although I may be blaming the wrong filter). As a lazy hack, Aeschylus now
generates a Makefile13 which sets
off a cascade of FFmpeg processes. While that does end up generating a number
of intermediate files, it can at least do much of the processing in parallel.
It’s not a quick process, but it’s just about the right
side of interminable. On my 2016 4 core desktop computer, it can process the 3
hours of input for Virtual Machine Warmup Blows Hot and Cold into a ready to upload video in under an hour and a
half. Someone more expert with video processing than I could probably improve
this substantially.
Clock synchronisation
Aeschylus works by using the wall-clock time of markers to extract portions of a video. Ideally Aeschylus would instruct the FFmpeg recording process that a marker has been set, and then FFmpeg could use its preferred clock to accurately associate the marker with the audio and video. Unfortunately, although I suspect FFmpeg might have a way of doing this (almost certainly involving “cues”), I wasn’t able to work out how to do so.
Instead, Aeschylus uses the wall-clock time since the Unix epoch for markers, forcing FFmpeg to also use Unix epoch timestamps for audio and video packets. Fortunately forcing FFmpeg to do this isn’t too difficult:
ffmpeg -hide_banner \ -use_wallclock_as_timestamps 1 \ -f v4l2 -i /dev/video0 \ -map "0:v" -copyts recording.nut
However, this raises the inevitable spectre of clock synchronisation. The basic problem is that clocks in various devices tend to run at slightly different speeds: even if you synchronise two different clocks, they drift apart over time. This is not merely a theoretical concern. For example, I recently observed noticeable audio phase issues from two devices’ clocks drifting apart only 20 seconds after starting recording.
I assumed at first that FFmpeg would always use a fixed-rate monotonic clock
– i.e. a clock which not only doesn’t go backwards but always goes
forwards at a fixed rate (e.g. isn’t affected by NTP) – when available.
Instead, if my poke around the source code is anything to go by, FFmpeg uses
several different clocks, often the normal system clock or sometimes a
monotonic clock. On Linux, for example, FFmpeg mostly uses
CLOCK_MONOTONIC (which doesn’t go backwards, but doesn’t
go forwards at a fixed rate) except for the v4l2 backend which you
can force to use the more sensible CLOCK_MONOTONIC_RAW (which goes
forwards at a fixed rate). Possibly because of the different clocks involved,
early versions of Aeschylus had huge problems accurately associating markers
with the recorded input, causing scene extraction to sometimes be off by
multiple video frames.
In the audio world, high-end devices solve this problem by allowing one device
to send its clock signal to another, so both are perfectly synchronised.
Although I couldn’t find any meaningful documentation for this feature, I
believe FFmpeg also allows this sort of synchronisation using the “,” syntax in
-map:
ffmpeg \ -use_wallclock_as_timestamps 1 \ -f v4l2 -i /dev/video0 \ -f sndio -i snd/0 \ -map "0:v,1:a" -map "1:a" -copyts recording.mkv
On my OpenBSD system, as far as I can tell, the sndio backend in
FFmpeg uses the non-monotonic system clock, and applies that to video frames as
they arrive. Aeschylus thus records marker time with (hopefully) the same
system clock. Using the non-monotonic system clock will almost certainly go
wrong in some cases (e.g. if NTP starts noticeably adjusting the clock
frequency), but I’ve got away with it so far.
There are probably already video recording systems that have most, if not all, of the necessary functionality to enable automatic video editing. For example, although I haven’t looked into it in depth, something like this plugin for OBS might do the trick though, if I’ve understood the documentation correctly. However, I think automatic video editing to be truly reliable needs marker setting to be accurate to below half a video frame’s length (for 24fps, 1 frame lasts about 0.04s). The OBS plugin seems to have an accuracy of 1 second, though I suspect that can be improved without difficulty.
Equipment
The internet is full of people detailing the lorry load of equipment they use to produce videos. Even if I could afford all of it, I wouldn’t have room to store it. Fortunately, one can produce decent looking videos with surprisingly little equipment.
For Don’t Panic! Better, Fewer, Syntax Errors for LR Parsers, I used my 2016 OpenBSD desktop computer, a RØDE Procaster microphone, an Elgato green screen, and a Logitech C920 webcam. I got the Procaster on the hope (mostly realised) that its rear noise rejection would make my creaky 15 year old keyboard less obvious; most people would probably be perfectly happy with a cheaper USB microphone. If I hadn’t wanted to “blend in” to the background, I wouldn’t have needed the green screen at all. The only lighting I used was good old fashioned English sunshine streaming through the window (which explains why I slightly change colour at some points in the video).
Cameras are a slightly touchier subject. The C920 is probably the most common stand-alone webcam, and is generally considered a decent webcam — but that doesn’t mean it’s a good camera. Frankly, webcams are a classic example of a neglected technology: the C920, for example, produces worse videos than a 10 year old mobile phone camera. At full scale, webcam images are blurry and noisy (or “grainy”). Fortunately, if you scale them down, and use a fairly heavy noise reducer, they don’t look too bad.
By the time of Virtual Machine Warmup Blows Hot and Cold I had acquired a Fujifilm x-mount mirrorless camera for photography which alongside a £12 HDMI capture card makes a good video camera too. Since the light in winter is much more variable than summer, I closed the curtains, and used the normal room light plus an £18 ring light (though it’s little more than a glorified desk lamp). A bit more lighting would have improved things, but even with this crude setup, the results are tolerable, producing good enough full-size images from the camera that I could inflict my full-sized face on viewers. However, my slightly old computer, combined with OpenBSD’s sluggish USB performance, means that I can only reliably capture 1080p footage at 24fps14.
Automating screen capture setup and teardown
When I first tried recording videos, I would manually change the video resolution (from 1900x1200 to 1900x1080), close a few obviously unused applications, start recording, and hope for the best. I ruined a couple of early videos by forgetting to change resolution or forgetting to close the web browser so chat messages popped up half way through. The most memorable mistake was when I left my mouse pointer visible just by the image of my head, in such a way that it looked like a cheap devil horn. Even without these cock-ups, the resulting screen capture was cluttered and distracting.
I soon realised that I needed to more carefully control what was running during screen capture, and that I needed to automate this so that I wouldn’t get it wrong quite so often. Aeschylus thus calls user-defined “setup” and “teardown” functions so that arbitrary code can do whatever it needs to get screen capture into order.
Exactly what you can and can’t do in this regard is heavily dependent on
your operating system and, if you’re on Unix, your desktop environment.
Fortunately on OpenBSD and XFCE I could automate everything I wanted, discovering some wonderful tools (e.g.
screenkey and unclutter) and techniques along the way.
For example, I send SIGSTOP (roughly equivalent to “ Ctrl+Z in
the terminal”) to bulky programs such as web browsers to ensure they don’t interfere
with the recording. I use xwinfo and xdotool to make
things like xfce4-panel (the application bar at the bottom of my
screen) invisible during recording.
It’s pleasantly surprising how far one can go in changing programs’
configurations from the command line. For example, I use bigger fonts in my
editor and terminal in videos than I do normally. xfce4-terminal
notices changes to its configuration file15 so I
can change from the old font to a new one with:
sed -i "s/^FontName.*\$/FontName=${NEW_TERMINAL_FONT}/g" \ ~/.config/xfce4/terminal/terminalrc
I do something similar with neovim, though I haven’t bothered trying to effect running instances: I have to load a new neovim to get the font size increase.
I also set various hot keys during setup, for example to enable gromit-mpx:
xfconf-query --channel xfce4-keyboard-shortcuts \ --property "/commands/custom/F12" \ --create --type string --set "gromit-mpx -t"
As this suggests, most of the necessary setup is relatively simple. There is one notable exception. I realised early on that if I made the background colour of my slides the same colour as the background of my desktop, viewers wouldn’t notice when I was moving from one to the other. While it looks like I’ve created a carefully constructed textual overlay, it’s actually just a PDF in a normal PDF viewer which is recorded as part of the X11 screen capture. It’s a cheap trick but an effective one! Unfortunately, I haven’t yet worked out a simple way of changing the background colour of all virtual desktops in XFCE so I have this horrific looking snippet:
r=`python3 -c "print((($BACKGROUND_COLOUR >> 16) & 255) / float(0xFF))"` g=`python3 -c "print((($BACKGROUND_COLOUR >> 8) & 255) / float(0xFF))"` b=`python3 -c "print(($BACKGROUND_COLOUR & 255) / float(0xFF))"` for wksp in `xfconf-query -c xfce4-desktop -l | \ grep -E "screen0.*(HDMI|monitor|eDP)-?[0-9]/workspace0" | \ cut -d "/" -f 1-5 | sort -u`; do xfconf-query --create -c xfce4-desktop -p ${wksp}/rgba1 \ -t double -t double -t double -t double -s $r -s $g -s $b -s 1 || true xfconf-query -c xfce4-desktop -p ${wksp}/image-style -s 0 || true xfconf-query -c xfce4-desktop -p ${wksp}/color-style -s 0 || true done
I feel sure that it must be possible to do better than that, but at least it works!
The overall effect is significant, as you can see if I run my Aeschylus setup script on the HTML I’m writing for this article:
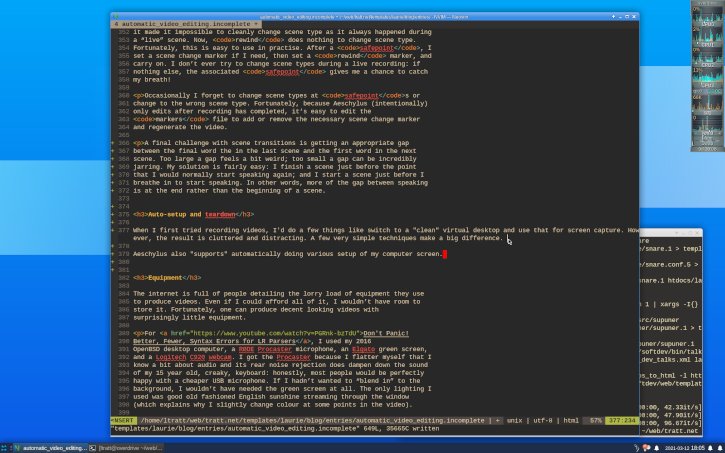
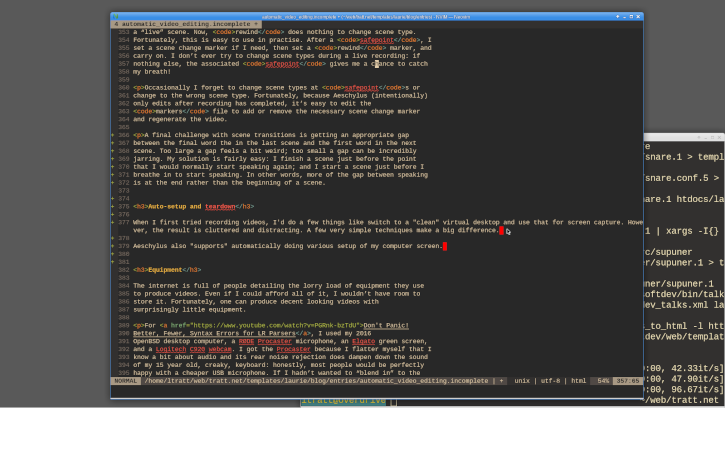
Of course, once I’ve finished recording, I want my desktop back to normal, so Aeschylus also calls a teardown function. Fortunately, once you’ve got the setup code working correctly, the teardown code is nearly always much easier to write.
Summary
Aeschylus is the worst written bit of software I’ve put my name to since I was about 15 years old and it will probably never be usable for anyone other than me. The reason that I’m willing to risk whatever minimal reputation I have is that I think Aeschylus fleshes out Vivek’s original idea a little bit further, and shows that automatic video editing works at a larger scale. I’m sure that the idea can be extended further — for example, I suspect that many people would like a way of replaying the last few seconds of the previous scene to help them decide what they want to say in the next retake of the current scene.
It’s important to stress that automatic video editing makes one part of video production easier, but it can’t change your delivery or, more significantly, create good content. It’s also not the right tool for people who want to produce videos with ground-breaking visuals, but it works well if you want to produce videos that look just about good enough that they don’t detract from their content. For me, and I suspect quite a lot of other people, that’s as high a bar as we need or want to jump over!
Addendum (2021-03-24): I’ve been pointed at a small number of tools which share some of Aeschylus’s goals. Probably closest in spirit is Gregor Richards’s plip, which makes it easy to record markers in OBS (neatly solving the clock synchronisation problem) and then edit out the chunks between markers in a custom editor. The commercial Descript tool takes a different approach, making it possible to do things like edit a video based on automatically transcribe text. I imagine that makes editing much easier though – like approaches which automatically remove silence – I expect that the resulting videos will contain more, and more jarring, transitions than I find comfortable. With luck, there will be further innovation in this area time goes on!
Acknowledgements: Thanks to Edd Barrett, Lukas Diekmann, and Vivek Haldar for comments.
Footnotes
“Immediately” is not an exaggeration. After seeing Sam’s talk, I reinvigorated my previously desultory efforts into investigating microphones, placing an order for a RØDE Procaster later that same day. It turned up in time for me to use it for the Ask Me Anything I did with Doug Lea 3 days later. In retrospect, that could have gone badly wrong: I had tested it for less than 5 minutes and on a different computer than the one I used to talk to Doug. As you can clearly see from the video, I hadn’t even worked out at what angle it might sound best. Fortunately, nothing went wrong, but that was more luck than judgment.
“Immediately” is not an exaggeration. After seeing Sam’s talk, I reinvigorated my previously desultory efforts into investigating microphones, placing an order for a RØDE Procaster later that same day. It turned up in time for me to use it for the Ask Me Anything I did with Doug Lea 3 days later. In retrospect, that could have gone badly wrong: I had tested it for less than 5 minutes and on a different computer than the one I used to talk to Doug. As you can clearly see from the video, I hadn’t even worked out at what angle it might sound best. Fortunately, nothing went wrong, but that was more luck than judgment.
At the time of writing, OBS has been at least partly ported to OpenBSD, although I haven’t tried using it.
At the time of writing, OBS has been at least partly ported to OpenBSD, although I haven’t tried using it.
Hardware encoding is much faster, but generally lower quality, both in terms of visual effects, and also in terms of how much the resulting file is compressed.
Hardware encoding is much faster, but generally lower quality, both in terms of visual effects, and also in terms of how much the resulting file is compressed.
For example, Audacity’s built-in compressor has a minimum attack time of 10ms, which is much slower than one wants for speech.
For example, Audacity’s built-in compressor has a minimum attack time of 10ms, which is much slower than one wants for speech.
This was exacerbated by the fact that it had not occurred to me to turn the monitor’s brightness down during recording and by the small desk I had at the time. For other reasons, I fixed the latter problem by purchasing this decent sized sit-stand desk — 6 months on, I remain both impressed and pleased with it!
This was exacerbated by the fact that it had not occurred to me to turn the monitor’s brightness down during recording and by the small desk I had at the time. For other reasons, I fixed the latter problem by purchasing this decent sized sit-stand desk — 6 months on, I remain both impressed and pleased with it!
Amongst the many surprising realisations I’ve had with video is that the common video formats have surprising problems. The mp4 format, for example, can contain lossless video but not lossless audio (unless you slightly ignore the standard). I found that out the hard way early on when after multiple rounds of processing, some of my test videos sounded like they’d been recorded on a landline! The mkv allows lossless video and audio but, to my surprise, can’t represent some framerates (including 24fps) accurately.
The nut format isn’t very well known, but I haven’t yet found a problem with it other than it’s apparently not supported by all players — but it’s supported by the video players I use, as well as sites like YouTube. During video processing I exclusively use lossless audio and video codecs (ffmpeg and H.264 in lossless mode) and I only ever upload lossless videos, so whatever processing YouTube and friends undertake does the least possible damage to the final video people watch.
Amongst the many surprising realisations I’ve had with video is that the common video formats have surprising problems. The mp4 format, for example, can contain lossless video but not lossless audio (unless you slightly ignore the standard). I found that out the hard way early on when after multiple rounds of processing, some of my test videos sounded like they’d been recorded on a landline! The mkv allows lossless video and audio but, to my surprise, can’t represent some framerates (including 24fps) accurately.
The nut format isn’t very well known, but I haven’t yet found a problem with it other than it’s apparently not supported by all players — but it’s supported by the video players I use, as well as sites like YouTube. During video processing I exclusively use lossless audio and video codecs (ffmpeg and H.264 in lossless mode) and I only ever upload lossless videos, so whatever processing YouTube and friends undertake does the least possible damage to the final video people watch.
Recorded music is an obvious analogy. Unless (and, often, even if) you listen to a live recording, you’re not listening to a recording of a band playing a song once through: you’re listening to multiple performances glued together to make that recording. Digital recording has allowed this to be taken to an extreme: tiny bursts of “perfect” playing can be glued together to make a recording which no human could ever achieve in a single take. I am not a fan of the results.
Recorded music is an obvious analogy. Unless (and, often, even if) you listen to a live recording, you’re not listening to a recording of a band playing a song once through: you’re listening to multiple performances glued together to make that recording. Digital recording has allowed this to be taken to an extreme: tiny bursts of “perfect” playing can be glued together to make a recording which no human could ever achieve in a single take. I am not a fan of the results.
To my surprise, some colleagues who are regular YouTube watchers are so used to such transitions that they didn’t even notice them. I remain unsure whether to be impressed or concerned by this.
To my surprise, some colleagues who are regular YouTube watchers are so used to such transitions that they didn’t even notice them. I remain unsure whether to be impressed or concerned by this.
Because my keyboard is so creaky, the noise of the key press and depress during transitions was awful. Aeschylus fades the volume down and then back up either side of the transition to lessen this.
Because my keyboard is so creaky, the noise of the key press and depress during transitions was awful. Aeschylus fades the volume down and then back up either side of the transition to lessen this.
The major exception is that FFmpeg treats video and audio very differently, and
not only refuses to coerce between the two, but won’t even accept one or the
other, even when it perhaps could. Thus one ends up with several filters which
do the same thing to audio as video (and vice versa), but accept only audio or
video (e.g. asetpts and setpts).
The major exception is that FFmpeg treats video and audio very differently, and
not only refuses to coerce between the two, but won’t even accept one or the
other, even when it perhaps could. Thus one ends up with several filters which
do the same thing to audio as video (and vice versa), but accept only audio or
video (e.g. asetpts and setpts).
To give you an idea, I discovered by trial and error a 700ms delay in a part of
FFmpeg I cared about. Absolutely baffled, I turned to Google to find someone
on a forum stating that the -muxdelay option defaults to 700ms.
This is, of course, not documented.
To give you an idea, I discovered by trial and error a 700ms delay in a part of
FFmpeg I cared about. Absolutely baffled, I turned to Google to find someone
on a forum stating that the -muxdelay option defaults to 700ms.
This is, of course, not documented.
vaguedenoiser is particularly slow. I previously used
hqdn3d, which is much faster, and gave good results on low quality
webcam footage. On higher quality mirrorless input, however, hqd3d felt like it
was smudging things a bit too much for my liking.
vaguedenoiser is particularly slow. I previously used
hqdn3d, which is much faster, and gave good results on low quality
webcam footage. On higher quality mirrorless input, however, hqd3d felt like it
was smudging things a bit too much for my liking.
The Makefile for Virtual Machine Warmup Blows Hot and Cold weighs in at
1396 lines.
The Makefile for Virtual Machine Warmup Blows Hot and Cold weighs in at
1396 lines.
Although some modern monitors can adapt their refresh rate to the content displayed, a safer bet is that most have a refresh rate that’s an integer multiple of 30. However, for the sort of videos I’m producing the difference between 24fps and 30fps isn’t too significant.
Although some modern monitors can adapt their refresh rate to the content displayed, a safer bet is that most have a refresh rate that’s an integer multiple of 30. However, for the sort of videos I’m producing the difference between 24fps and 30fps isn’t too significant.
Unfortunately, xfce4-terminal does go a bit wonky sometimes during
configuration changes, notably it sometimes gets confused and changes its
window size or displays the wrong font. This seems to mostly happen when the
font size is decreased, although I have no idea why this might be the case.
Unfortunately, xfce4-terminal does go a bit wonky sometimes during
configuration changes, notably it sometimes gets confused and changes its
window size or displays the wrong font. This seems to mostly happen when the
font size is decreased, although I have no idea why this might be the case.