The use of AI (Artificial Intelligence) techniques, specifically ML (Machine Learning) and its various sub-fields, is changing many fields and undoubtedly will change more in the coming years. Most of us are at least generally familiar with the idea of using ML to identify patterns in data. More recently Generative AI (“GAI” for the rest of this post), in the form of systems such as ChatGPT and Stable Diffusion, has made itself more widely known. Rather than simply classify new data, GAI can, as the name suggests, generate new outputs that conform to the underlying patterns contained in the model1. Existing ML systems, in general, and GAI systems particularly, are almost certainly the harbingers of further advances. This inevitably leads to speculation about “what’s next?”
From my perspective, the obvious question is: how might ML and GAI change programming? In particular, the rapid advances in GAI have led many to assume that we will gradually do away with programming as a human activity. Although it’s rarely spelt out explicitly, this implies that a GAI system can take in a human description (or “specification”) and produce usable software from it. At a small scale, this is already possible, with the best known example being CoPilot.
When it comes to the generation of software, GAI and programming seem surprisingly similar: they both take in a specification and produce software as output. In each case, both fill in gaps in the inevitably incomplete specification in order to make complete software. However, the two approaches take a fundamentally different approach to understanding and filling in gaps in specifications: programming forces humans to use their knowledge and experience to manually fill in the gaps; GAI uses the model it has learnt from existing programs to automatically fill in the gaps. This might seem like a small, perhaps even a pedantic, difference, but I believe it has significant consequences.
In this post I’m going to try and explain why I think GAI, at least in its current forms, is unlikely to be able to fully replace programming. In order to do that, I first look at the relationship between programming and software in a slightly different way than most of us are used to. Having done that, I’ll then explain how I think GAI is different than programming when it comes to generating software. I’ll finish by giving some very general thoughts about how ML techniques (including, but not only, GAI techniques) might influence how we go about programming.
I hope that this post does not come across as anti-ML/GAI, Luddite-esque, or even just grumpy. There is a lot to look forward to from these new techniques, but I believe we’ll only maximise their utility if we think about where they’re most likely to help. I also hope that this post does not come across as making definitive statements about what is possible. I can’t predict the future with certainty: ML and GAI will evolve in ways that none of us can foresee, and there is always the potential for entirely new techniques to emerge that will completely change what we understand to be possible. However, if you’re interested in programming, and wondering how ML and GAI might or might not affect you, I hope this post will at least give you some food for thought!
Programming turns specifications into software
Those of us who enjoy programming tend to do so because, not in spite of, the volume of detail it requires us to manage. We use, often to great effect, algorithms and data structures of astonishing complexity and subtlety — skills that take years to learn. It’s easy for us to forget that programming has limited purpose in and of itself: the goal of programming is to create software. Viewed in a certain light, programming can be seen as the anti-software, continually slowing us down in, or even preventing us from, creating the software we want.
However, useful software cannot appear from nowhere: someone has to specify what the software should do, and someone, or something, has to create software that satisfies the specification. Seen in this light, it becomes clear that programming is simply a mechanism for turning a specification into software.
Is programming the best mechanism of turning specifications into software? There are certainly cases when the answer is “no”, whether that’s due to the use of domain specific languages, or glueing existing systems together in some way. That said, the history of software so far suggests that, to misquote Churchill, programming is the worst mechanism for turning specifications into software except for all those other forms that have been tried from time to time.
The reason for this is simple: programming involves lots of details because we want software to do very detailed things. Some of that detail relates to obvious user-facing functionality that users find easy to capture in a specification (e.g. “the software for my warehouses must be able to cope with stock being split into smaller quantities and shipped to other warehouses before going to a customer”). However, much of the detail that we expect in good software is absent in a typical specification.
I find it easier to understand this by considering the problem in reverse. For example, imagine if you converted all the hashmaps in your favourite bit of software into arrays: you’d have exactly the same “functionality” but your software would probably become unpleasantly slow. In other words, the (correct) use of hashmaps is part of the specification — however, very few non-programmers would have thought to specify their use. As this suggests, user-level specifications are almost never complete — they leave out things that a good piece of software must address. Programming is the means by which we both understand what’s been left out and fill in the resulting blanks.
Recent history provides an interesting example of the relationship between programming and specifications. In the 1980s, software was growing rapidly in scale, but growing alongside it were reliability problems: put bluntly, most software wasn’t very good. As a mechanism to increase reliability, there was a strong movement towards formal methods. For our purposes we can consider this to be a marriage of specification languages (sometimes as part of more general “methods”) such as Z, VDM, or B and the proving of properties about those specifications. Once a formal specification of software had been created, it would either be automatically converted into a running program, or a team of semi-skilled programmers tasked with mechanically converting it into a normal program. Either way, many classes of errors in normal software would be at least minimised, and possibly eliminated entirely.
Formal methods undoubtedly offer us the possibility of more reliable software, but are rarely used on big systems2. There are various explanations for this3, but personally I think it’s mostly because creating a complete formal specification is at least as hard as the equivalent programming. This is because such a specification needs to have all of the information we create when programming, plus, in general, extra information that makes proving properties useful.
Using GAI to generate software from specifications
At this point, I hope that you’re prepared to consider that a) software must come with a specification (whether explicit or implicit) b) programming is about turning specifications into software c) complete specifications are at least as hard as programming.
We now need to narrow down what GAI can realistically mean, at least at a high level. I expect most readers have seen the recent explosion in ML-based image generation using diffusion models. A simple textual specification4 from a human allows such systems to create a variety of high quality images. If the images created aren’t to your liking, you can extend or correct your specification, and generate new images. Crucially, the specification need not be complete: if I ask for an image of “bread”, I don’t have to specify what colour each individual pixel should be, or even what colour the bread should be.
Exactly the same idea is plausible for software: we create a specification (whether as natural language or not is irrelevant), and a GAI system can then generate software from it. CoPilot, for example, already does just this (albeit at a smaller scale than an entire piece of software).
Just as with image generation, the quality of both the model underlying the GAI and the specification itself are crucial in determining the quality of the generated output. If I ask a GAI system to generate a large bit of software from a specification as vague as “I want software that can track the incoming and outgoing stock from my warehouse” I’m probably not going to get what I hoped for: the GAI system will have filled in countless implicit gaps in my specification (ranging from the format of stock IDs to the kind of user interface I want). However, just as with image generation, I can extend and correct my specification and regenerate the software I want as many times as I want.
In the context of software, GAI opens up a tantalising possibility: rapid iteration on specifications. One constant in software is that we almost never fully know what the software should do until we see it working, at which point we realise that our ideas, and the software itself, need changing, often radically: no specification survives first contact with the user5. Radical changes to specifications can require vast programming effort to adjust the related software. In contrast, in GAI, correcting a specification could conceivably lead to near-instant changes in the software produced.
It thus seems that all I will need to generate software with GAI is a small degree of skill in specifying software, and sufficient patience to extend and correct a specification until the output is as I want. However, there are important differences with image generation, which I’m going to put into three buckets.
Programming is unforgiving of approximations
None of us enjoys software that fails to work correctly, whether it crashes, or simply produces an incorrect result. In either case, the software has violated our (probably implicit) specification of what the software can do. Another way of thinking of this is that the software is an approximate implementation of the software we wanted.
Because of the many jaw-dropping uses ML has been put to, we can easily overlook that it is also an approximation technique of sorts. There’s absolutely nothing wrong with this: if ML models didn’t approximate (or, looked at another way, simplify) the thing they’re modelling, they would take impossibly long to train, and be impossibly large. In many cases, we can’t even enumerate what we’d really like to model, settling for proxies instead. For example, a system like ChatGPT might seem to be modelling all human knowledge, but instead it models what’s been written down about human knowledge as a proxy. The differences between the “real” thing and the proxy are one reason why GAI systems can produce nonsense output.
In this context, programming is a specific – but still large! – subset of human knowledge. We cannot currently enumerate that human knowledge, so instead our training proxy must be existing programs. These are inevitably incomplete in the way they represent what programming is truly about: turning specifications into software. Using models derived in this way seems to me to inevitably mean that ML-based GAI will be an approximation of what we would hope for — they’re less likely to fill in gaps as well as programmers and, at least currently, less likely to know when to ask users to clarify their specification than a programmer6.
That means that someone (or something) is always going to have to validate the software produced by a GAI system against the intended specification. Of course, this is not something unique to GAI-produced systems: code reviewers already do this for pull requests, and QA teams already do this for entire software systems.
However, it seems likely that when asked to produce a system that hasn’t exactly been seen before, GAI systems will often end up in the programming equivalent of the uncanny valley: producing initially reasonable looking code that contains a surprising number of minor mistakes. Human review is, in my experience, particularly bad at finding those sorts of minor mistakes.
Perhaps instead we could use another AI system to validate the systems produced? This might ameliorate the situation, but it’s unclear to me whether adding two (or three or …) approximations could, in general, get us to a level of correctness we’d feel comfortable with. Of course, if we had a formal specification, we could use that to validate the software: but, as we saw earlier, virtually no-one ever has a formal specification.
It therefore seems likely to me that humans will end up having to do most of the validation of GAI generated systems. This is likely to be made more difficult because GAI systems are likely to produce output without really being able to tell us why the output looks as it does. There is a huge desire to have “explainable AI”, but I must admit that I can’t understand how this could ever work with ML. By its very nature, it slurps in huge quantities of data and gradually derives relationships: when put to use, there is no simple way of providing an answer for for “this input led to that output”.
Specifications scale non-linearly
How many iterations of extending and correcting a specification will I need to generate good software? For small chunks of software – perhaps roughly the length of a typical function – the answer might be “not much”, with perhaps 1 or 2 iterations of extending and correcting all that’s necessary. For some small examples, this is undoubtedly quicker than the equivalent programming, as can be seen from CoPilot.
However, my belief is that this is unlikely to scale very far: as soon as we want to generate even moderately large chunks of software, the specifications will soon trend towards the same size7 as the equivalent program. I tend to think of software as scaling non-linearly with complexity, so a diagrammatic representation might look as follows:
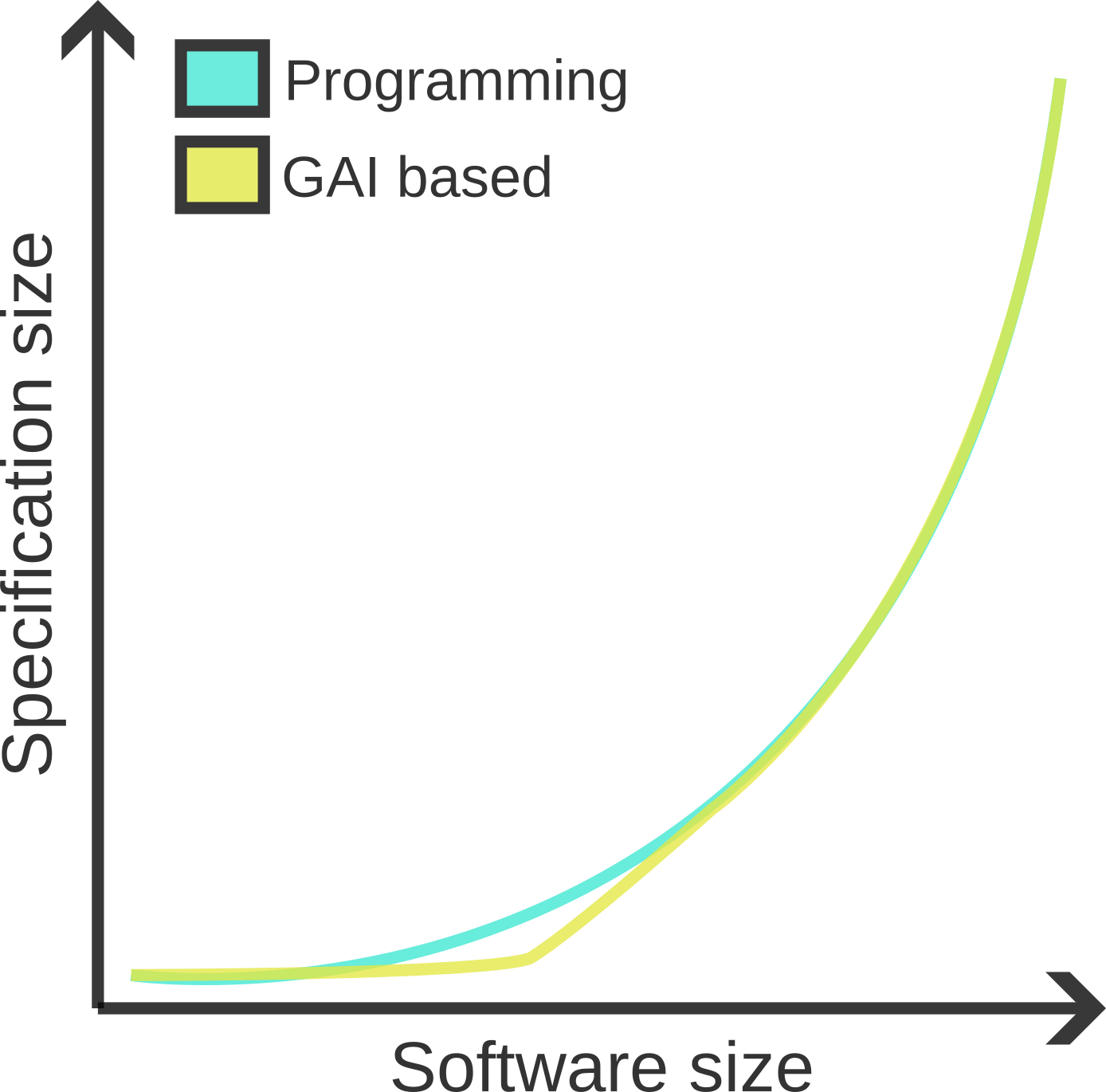
Scale tends to bite quickly: I’m hardly likely to generate warehouse software with exactly the features I require in 1 or 2, or 10, or even 100 iterations. As we saw earlier, good software also contains details that one might not immediately think of as being part of a specification. For example, if a GAI system generates warehouse software that runs too slow, simply adding “I want the same software but faster” or even “make looking up customer orders sub-linear speed” to my specification seems unlikely to do the trick. Instead, I’m probably going to have to do something close to saying “use a hashmap to store and lookup customer orders”.
This implies that, if GAI systems are to generate high quality software of any meaningful size, the people driving that generation will require nearly all the same skills as today’s programmers. They will also probably need to expend about the same level of thought on adjusting the software to fit the (incomplete) specifications as today. Perhaps there will be a little less typing of ASCII / UTF-8 characters, but a solid understanding of abstraction, algorithms, and data-structures, and high degrees of patience and perseverance seem likely to remain fundamental skills.
Minimising the effects of change allows software to evolve
When I try and convince people to add meaningful quantities of tests to their software, I make clear that my experience is that such tests only really pay off in the long term. The reason for this is that software is always subject to change, but the older and larger your software, the more scared you will be of changing it, for fear of breaking seemingly unrelated parts of the software. Larger test suites help reduce that fear by giving you greater confidence that your changes are not causing unintended consequences.
GAI seems likely to make unintended consequences more likely, because even small changes in a specification might cause a ripple of changes in the generated system. Understanding what has changed in the system as a whole, and deciding whether those changes are acceptable or not, will probably be hard. It might seem that all we need to do is to control what it means to refine a specification, but history suggests this is hard: “refinement” in formal methods has turned out to be a more challenging problem in practise than one would have expected from theory. It’s possible that the iterative process of changing a specification and checking how the GAI system has adjusted the software will become a task with a distinct Sisyphean tint.
Where ML might improve programming
Just because I’m sceptical that ML/GAI will generate whole systems, and thus replace programming, doesn’t mean that I don’t see a big place for these techniques in programming. Enumerating all the possibilities is far beyond my abilities, but a few examples will hopefully give you an idea of what we might have to look forward to. Some of these are already being publicly worked on; and many more are probably being worked on behind closed doors.
For example, one of the techniques that’s recently helped to improve software reliability has been fuzzing, where semi-random data can be astonishingly effective at finding bugs. GAI techniques seem likely to push this sort of idea much further than has previously been possible by deeper learning from previous example inputs. For example, even if a GAI system generates mostly incorrect inputs, it is likely to generate a reasonable number of inputs that tickle unexplored code paths. Similarly, I suspect ML will be good at inferring unexpected properties for property-based testing. It might be the case that unexpected properties it infers and then “proves” true (in the sense that no test case can be found to invalidate them) might be just as illuminating as properties that it infers and then disproves.
While ML probably isn’t the right technique to directly optimise code, it seems likely to be extremely effective at suggesting optimisations. For example, ML techniques will probably be good at statically detecting common small-scale inefficiencies, allowing humans to quickly review changes. ML techniques might also be good at ingesting profiling data and suggesting optimisations based on that.
More speculatively, ML techniques might finally give us a means to understand large software systems. At the moment, our only effective means of explaining a large system (other than diving into the source code) is manually written documentation. Perhaps ML techniques will be able to uncover, and present in a digestible manner, patterns in large systems that only eventually reveal themselves to the most diligent and patient humans.
I could go on, but I hope you get the idea: ML and GAI have a lot to offer programming, if we can work out how best to put them to use.
Acknowledgements: thanks to Martin Berger and Hillel Wayne for comments.
Footnotes
There’s no reason that GAI systems have to be based on a particular ML technique, or even ML itself. But, to make my life and the readers a little easier, I’ll assume that GAI systems are ML based for the rest of the post.
There’s no reason that GAI systems have to be based on a particular ML technique, or even ML itself. But, to make my life and the readers a little easier, I’ll assume that GAI systems are ML based for the rest of the post.
This is not to say that formal methods have not had a big impact: it’s just not been the impact that was originally envisioned. The most common use of formal methods these days is indirect: the various tools (often called just “static analyses”) we use to analyse source code (sometimes with annotations) all trace themselves back to formal methods. This impact continues to grow and has become more profound than I for one would have guessed even a decade ago. I now make frequent use of tools and techniques that derive from formal methods.
This is not to say that formal methods have not had a big impact: it’s just not been the impact that was originally envisioned. The most common use of formal methods these days is indirect: the various tools (often called just “static analyses”) we use to analyse source code (sometimes with annotations) all trace themselves back to formal methods. This impact continues to grow and has become more profound than I for one would have guessed even a decade ago. I now make frequent use of tools and techniques that derive from formal methods.
In 1996, Tony Hoare, one of of the driving forces behind formal methods, wrote a wonderfully honest assessment of how software had improved in reliability despite the lack of use of formal methods. Quoting briefly from his How did software get so reliable without proof?:
Twenty years ago it was reasonable to predict that the size and ambition of software products would be severely limited by the unreliability of their component programs… The arguments were sufficiently persuasive to trigger a significant research effort devoted to the problem of program correctness… Fortunately, the problem of program correctness has turned out to be far less serious than predicted.
It’s worth reading the whole thing, since its argument is more subtle than I can briefly summarise, crediting better management, testing techniques, and what I would call “reliability in depth” (what Hoare calls “over-engineering”) for the improvement in software reliability. However, I don’t think that Hoare fully addresses the “specifications are difficult” aspect that most concerns me.
In contrast, Hillel Wayne’s “why don’t people use formal methods?” does touch on this issue and many more. It’s an extensive overview of what formal methods is and can be, and what the factors that limit widespread use are.
In 1996, Tony Hoare, one of of the driving forces behind formal methods, wrote a wonderfully honest assessment of how software had improved in reliability despite the lack of use of formal methods. Quoting briefly from his How did software get so reliable without proof?:
Twenty years ago it was reasonable to predict that the size and ambition of software products would be severely limited by the unreliability of their component programs… The arguments were sufficiently persuasive to trigger a significant research effort devoted to the problem of program correctness… Fortunately, the problem of program correctness has turned out to be far less serious than predicted.
It’s worth reading the whole thing, since its argument is more subtle than I can briefly summarise, crediting better management, testing techniques, and what I would call “reliability in depth” (what Hoare calls “over-engineering”) for the improvement in software reliability. However, I don’t think that Hoare fully addresses the “specifications are difficult” aspect that most concerns me.
In contrast, Hillel Wayne’s “why don’t people use formal methods?” does touch on this issue and many more. It’s an extensive overview of what formal methods is and can be, and what the factors that limit widespread use are.
I’m deliberately not using the now-standard term “prompt”: to me “specification” is clearer in general, and definitely clearer when we’re comparing ML techniques and programming.
I’m deliberately not using the now-standard term “prompt”: to me “specification” is clearer in general, and definitely clearer when we’re comparing ML techniques and programming.
Moltke wrote that “No plan of operations extends with any certainty beyond the first encounter with the enemy’s main force” not “No plan survives first contact with the enemy”. At this point, the latter is so deeply embedded in our collective consciousness that trying to use the correct quote seems pointless.
Moltke wrote that “No plan of operations extends with any certainty beyond the first encounter with the enemy’s main force” not “No plan survives first contact with the enemy”. At this point, the latter is so deeply embedded in our collective consciousness that trying to use the correct quote seems pointless.
One of the defining features of the new generation of ML-based techniques is overconfidence: they present completely incorrect results in the same way as correct results. I’m sure that various techniques (including, but not limited to, human-programmed post-filters of some sort) will reduce the number of incorrect results, but it’s hard to see how this problem can be removed completely.
One of the defining features of the new generation of ML-based techniques is overconfidence: they present completely incorrect results in the same way as correct results. I’m sure that various techniques (including, but not limited to, human-programmed post-filters of some sort) will reduce the number of incorrect results, but it’s hard to see how this problem can be removed completely.
Exactly what metric to use for “size” isn’t too important: one might even choose to think of this as the even vaguer notions of “effort” or “complexity”.
Exactly what metric to use for “size” isn’t too important: one might even choose to think of this as the even vaguer notions of “effort” or “complexity”.