In the last year or two there has been a slow but steady trickle of articles attempting to account for UML’s lack of long-term success (if you have time for only one, I suggest Hillel Wayne’s article). As fate would have it, I had some involvement in UML standardisation in the early 2000s, so I saw some of the going-ons from the “inside”. Although I’ve touched on this before, I’ve never written about my experiences in detail because I was worried about offending people who I like. 17 years after the fact, I hope that the likelihood of anyone being offended is fairly low.
In this post I’m going to try and explain some of the factors that I think contributed to UML’s downfall. To some extent this is a historical document, at least of my perspective. But, with the benefit of hindsight, I feel there are general lessons to be drawn about how both group dynamics and standardisation can develop in unfortunate ways. Be forewarned that I only saw part of what was going on (so I will be unaware of possibly important details), I didn’t write a diary (so I will recall things incorrectly), and my recollections are bound to reflect my biases (my ego will inevitably encourage me to relay the story in a way that presents me in a better light than I deserve).
Background
People had long created diagrams to document important aspects of software. Over the course of the late 80s and early 90s, three diagramming styles or, more grandly, “methods”, had started to become popular: the Booch, Jacobson, and Rumbaugh methods. After two merges, these three methods were combined to create UML (hence the “U” standing for “Unified” in UML), released as a standard through the OMG (Object Management Group), a standards body that had previously been best known for the CORBA standard.
The standardisation of UML coincided with, and was probably a necessary precondition of, a rapid increase in its use. From my perspective as an undergraduate in the late 1990s, Martin Fowler’s UML Distilled book was also an important part in UML reaching a wide audience. Class diagrams, in particular, became extremely common, and a simplification of UML’s class diagram syntax had come close to being a lingua franca by 2000. Here’s a simple example:
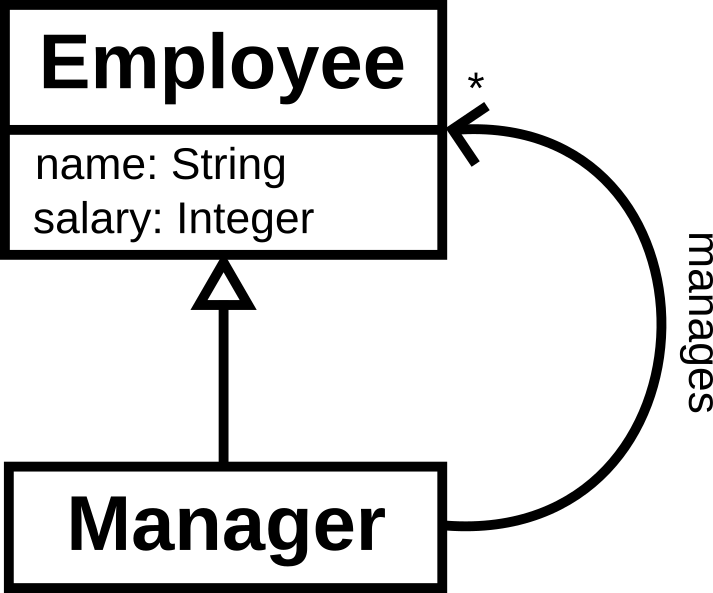
This shows two classes: an Employee class; and a subclass (the
arrow with the hollow triangle) of employees who are Managers. All
employees have a name and a salary. Managers manage zero or more (the “*” near
the end of the arrow) employees.
At this point, I hope you’ll forgive me if I briefly explain my involvement so that you have the necessary context to interpret the rest of this post. I started a PhD in September 2000, though my would-be supervisor soon left for a start-up. That left me in need of a new supervisor and by summer 2001 I had found someone willing to take me on. Tony Clark remains an inspiration for me: technically gifted, thoughtful, and with an excellent sense of humour. He didn’t deserve to be lumbered with a loud-mouth pea-brain like me, but he never once complained! Tony was part of a group of academics and industrialists working towards UML 2.0. It was through that work that I gradually got sucked into the world of UML standardisation. I had no idea what I was doing in 2001. In 2002 I started to get the hang of things and contributed some bits and pieces. In 2003 everyone else in my research group left for a start-up: I chose to inherit their responsibilities, forcing me to become a minor player in standardisation in my own right. By early 2005 I had become thoroughly disillusioned and moved onto other things.
The situation in the early 2000s
The situation in 2000 was, roughly, that UML had been much more successful than anyone expected. Although UML was mostly being used for sketching designs (i.e. a communication mechanism between humans), some important industries (e.g. aviation) were starting to think of it as a plausible basis for their more formal approaches to creating software (i.e. a communication mechanism between human and machine)1. A growing industry was creating UML-based tools. By far the biggest player was IBM (who soon acquired Rational, the company that had incubated UML2 and created the most popular UML-based tool). It’s difficult to imagine now, but in 2000 IBM was not only rich in money and people, but still had the ability to nudge the entire software industry in its desired direction. IBM’s involvement was implicitly taken as a sign that there was money to be made in UML.
The problem was that UML version 1 was manifestly unsuited to the ambitions IBM and others had for it. Not only was the standard itself somewhat vague, but what it was defining was rather vague too. In may ways, UML’s original sin was that class diagrams – by far the most widely used part of UML – were largely designed as a diagrammatic notation for the most common object orientated programming language of the day — C++. After Java’s success in the late 90s, UML was extended so that it could also somewhat accurately represent some aspects of Java, but the mechanisms used3 were widely perceived as an ugly hack, and clearly wouldn’t scale to supporting arbitrary numbers of programming languages.
Gradually a consensus emerged: what was needed was for a completely new version of UML that could precisely represent software; and that new version of UML itself needed a rigorous definition so that customers would be able to use a variety of tools from a growing set of UML tool vendors. From this consensus emerged the vision for what became UML 2.
Standardisation
Since it precedes my involvement, I’m not entirely sure when work started on UML 2. My best guess is that the general idea started in 1999, and started to pick up speed during 2000. Work continued in parallel on new versions of UML 1.x standardisation, since that was the bread and butter of all the participants involved. All UML standardisation was done under the auspices of the OMG who, based on my later experiences, were almost certainly active participants in encouraging the formation of UML 2.
A fundamental question was: what use cases should UML support? By the time I came along, it was taken as a given that UML should be used as the basis of “software modelling”, an intended step-change in the way software was engineered. Taking direct inspiration from architectural blueprints, the aim was for UML to be used to give software more solid foundations. Gradually (and we’ll get more into this later), this frequently came to be taken to mean that software would be partly or wholly created directly from UML models. This ambitious aim presented two separate challenges to standardisation.
Rigorous underpinnings
The early UML 1.x standards were fairly standard prose documents, often vague, and missing much desirable detail. Tool vendors — who had often updated pre-UML tools to support UML — disagreed on fundamental aspects. Sometimes, particularly when older tools were involved, this was intentional; sometimes it was unintentional when people interpreted the standards in different ways. Either way, interoperability between tools was poor. The situation was at best embarrassing, and at worst a serious impediment to UML’s success.
The standardisation community universally agreed that UML 2 would need rigorous underpinnings. However, no-one knew exactly what “rigorous” should mean, or how one should go about achieving it. Gradually, a small group of academics4, who did have an idea of what rigorous could mean and how one could go about it, became involved in standardisation.
Their idea was, in essence, to use a subset of UML5 to give “full” UML a denotational semantics. Practically speaking, it meant that one could “grow” the UML specification from a small core, using UML class diagrams for much of the semantic definitions, and UML’s constraint language (OCL) for fine-grained semantic specifications.
However, while much of the standardisation community liked the general sound of this, few of them had the background needed to understand the details. This is not a criticism — I was lucky enough to be able to work with some of the key people, and it took me a year or more of blindly copying what they were doing before the underlying concepts sunk in. Most people did not have such an opportunity. It didn’t help that using UML class diagrams led to very verbose semantic definitions, leading to the development of meta-programming-esque techniques to reduce some of the drudgery — which confused people even more!
This meant that one would regularly be in a room of 20 people arguing over definitions, with at most 1 or 2 people realistically capable of translating the outcome of the discussion into rigorous (or, perhaps more accurately, semi-rigorous) semantics — and probably only the same 1 or 2 people capable of fully understanding the results. Once the core academics had wandered off to greener pastures, most (though not quite all) of the relevant skills left with them.
By the time I left the UML standardisation world, it seemed to me that the community was gradually lowering its expectations to somewhere between UML 1.x’s vagueness and “true” rigour. Looking at the current UML 2.5.1 specification seems to suggest that was what happened. It’s plausible that this lowering of expectations would have happened anyway. In particular there was a subset of (often, but not always, small) tool vendors who wanted to spend the bare minimum on updating their software. While they lacked a clear strategy for slowing down the rate of change, they sometimes achieved this effect anyway through various tactics, including simply running the clock down in physical meetings.
What to standardise?
The ideal of “standardisation” has traditionally been to look at what’s working already and define that as a standard. While the reality of standardisation has often been rather more muddy than the ideal might suggest, UML 2 took this to rarely seen levels.
As I mentioned earlier, by 2000 the standardisation community had decided that UML should be the basis of a new way for creating software. By late 2000, the OMG had actively corralled people behind a new vision, called “Model Driven Architecture” (MDA). The idea was to automatically generate vast swathes of code from UML models. Here’s a direct quote from the MDA document6:
Whether your ultimate target is CCM, EJB, MTS, or some other component or transaction-based platform, the first step when constructing an MDA-based application will be to create a platform- independent application model expressed via UML in terms of the appropriate core model. Platform specialists will convert this general application model into one targeted to a specific platform such as CCM, EJB, or MTS. Standard mappings will allow tools to automate some of the conversion.
…
The next step is to generate application code itself. For component environments, the system will have to produce many types of code and configuration files including interface files, component definition files, program code files, component configuration files, and assembly configuration files. The more completely the platform-specific UML dialect reflects the actual platform environment, the more completely the application semantics and run-time behavior can be included in the platform-specific application model and the more complete the generated code can be. In a mature MDA environment, code generation will be substantial or, perhaps in some cases, even complete. Early versions are unlikely to provide a high degree of automatic generation, but even initial implementations will simplify development projects and represent a significant gain, on balance, for early adopters, because they will be using a consistent architecture for managing the platform-independent and platform-specific aspects of their applications.
The basic idea underlying MDA was that people creating software would first create a “PIM (Platform Independent Model)” — think, a programming-language neutral UML class model. From that (ideally by pushing a button) they would create a more detailed “PSM (Platform Specific Model)” — think, a class model with annotations for a particular programming language (e.g. Java). Once the PSM had been suitably tweaked, it would be transformed into “low-level” programming language code that users would compile and run.
For example, if I used the class diagram from earlier in the post as my PIM:
and I wanted to eventually create a Java system I might transform it into the following PSM:
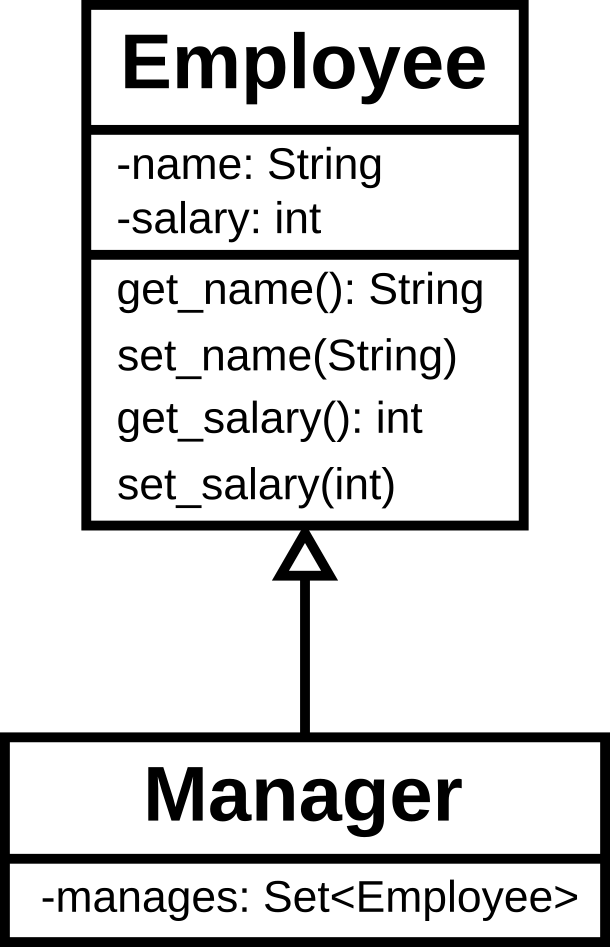
The PSM makes more details concrete: I’ve specified the visibility of fields
(“-” means “private”); and I’ve started using specific Java types
(int and Set). I might then generate Java code along the lines of:
class Employee { private String name; private int salary; public String get_name() { return this.name; } public void set_name(String name) { this.name = name; } public int get_salary() { return this.salary; } public void set_salary(int salary) { this.salary = salary; } } class Manager extends Employee { private Set manages; }
Soon the vision for what should be standardised for UML became mixed together with “what does MDA need?” It’s thus important to delve into the MDA vision in more depth.
The MDA vision
By the time I had become involved in things, most of the nuance in the MDA text I quoted above had disappeared. It was largely taken as a given that only the most talented people in an organisation would be involved in the creation of PIMs; a cadre of second-class citizens would then have to engage in the drudgery of creating a PSM from a PIM; and no-one would need to worry about the code generated from the PSM.
The deep flaws in this vision might be obvious to most readers, but the
standardisation community, intentionally or not, trained itself over time
to avoid thinking about them. The most glaring flaw
is: where would “behaviour” (i.e. the nitty gritty details of what a program
should do) be specified? UML class diagrams are fine for expressing program
structure, but they don’t tell you what a function should actually do. It’s
probably fairly obvious what get_salary should do, but what
if I’d added a function print_names to Manager
in the PIM? Should it have printed out employee names? in alphabetical
order? etc. Sometimes OCL constraints on a function definition would make clear
what the function should do, but most of us find it difficult to provide
precise constraints for complex behaviour. UML did have state machines, but they
are only really suitable for expressing certain kinds of behaviour. UML’s sequence
and collaboration diagrams are even more limited in their abilities to express
behaviour.
Once in a while, someone would bring up the problem of specifying behaviour: they would in general either be ignored, or told that the problem was so trivial as to not be worth worrying about. Far, far more energy was spent arguing about what level of detail should be modelled in PIMs and PSMs — I remember day-long arguments in windowless hotel rooms with people arguing about whether a certain detail belonged at the level of PIM or PSM.
Perhaps only one piece of software tried to make the true MDA vision a a reality — Compuware’s (long discontinued) OptimalJ. It was backed by a large team but it was a beast of a thing that brought normal computers of the day to their knees7. I had to write an evaluation of OptimalJ and soon realised how flawed the vision it was trying to implement was. Yes, I could create a class diagram as a PIM; press a button and create a PSM; and press another button and generate Java code. But the Java code had all sorts of holes in it that I had to fill in — and if I changed the model in any way, half of the code I’d written would no longer compile, let alone run correctly. In other words, OptimalJ automated the most trivial things, leaving all the hard work to the end user. The team behind OptimalJ were talented and hard working, but what they ended up showing was that MDA not only failed to improve programmer productivity, but actually slowed down development!
At the same time, many OMG members, and the OMG itself8 in the form of its charismatic leader, started putting increasing efforts into selling the MDA vision to the wider software community. I only realised how much impact this was having when I started to get asked by normal programmers questions along the lines of “I hear this MDA / UML thing is going to automate our jobs away?” My standard answer went along the lines of “it’s mostly aimed at non-programmers who want to create simple software” which, I think, reassured the people I spoke to. However, the fact that they asked the question showed that MDA’s marketing was starting to work. The question soon became: could the community make the reality of MDA match the vision?
The rise and fall of QVT
A fundamental idea underlying MDA was that PIMs needed to be transformed into PSMs and PSMs transformed into code. Slowly but surely it became clear to the standardisation community that such transformations were much more difficult than first thought. By 2002 this was recognised to be a significant problem. The community thus decided that what was needed was a new standard for model transformations. For reasons that I’ve now forgotten (or perhaps never knew) this ended up with the unwieldy title “QVT (Queries-Views-Transformations)”.
The QVT call for proposals went out in (I think) late 2002 or early 2003. A few months later 8 proposals had been created9, some of them in a literal burst of late-night activity. The core of the proposal I was involved in derived from a single afternoon’s discussion, which we then worked up into a semblance of a document over a few weeks. Astonishingly, our half-baked proposal was soon considered one of the “leading” proposals, which tells you something about some of the rest!
There is a fundamental tension in the sorts of transformations MDA, and thus QVT, needed, which I’ll simplify as follows. “Imperative” (think normal programming language) transformations explicitly specify the sequence of steps needed to transform an input to an output (e.g. “for each element in E, create an element E’ by calling the function f”). “Declarative” (think Prolog) transformations specify the relationship between the input and output (e.g. “for each element in E there is an output element E’ of the form X”), leaving an “engine” to work out how to make the input and output correct with respect to the specification. Imperative transformations are easy to write but are hard to rerun non-destructively: if you’ve changed the output, it’s difficult to then change the input, and see changes in the input reflected sensibly in the output. Declarative transformations are hard to write (particularly when the relationship between input and output is complex) but hold the promise of continually reordering the input and output, even when both have been changed independently.
Some of the QVT proposals asserted that only fully-imperative transformations were needed; some that fully declarative transformations were possible; and some (like the one I was involved with) tried to pretend they could span both dimensions. How could such disparate approaches end up as a single standard?
OMG meetings were at that point held 5 times a year in person (a level of travel that now horrifies me!), so we had many opportunities to try to find a compromise. However, compromise was rather hard to find. At one extreme was a camp that wanted to put a badge on their existing imperative programming language and call it QVT. At the other extreme was a camp that believed one could specify first order logic constraints and always efficiently find an optimal solution (something that would lead to the known laws of mathematics being rewritten).
The proposal I was involved with was much less concrete. Partly influenced by the PIM/PSM idea, our proposal proposed allowing high-level abstract definitions of transformations (what we called “relations”) and low-level implementations (what we called “mappings”). Relations were intended to be represented with UML-ish diagrammatic syntax, but we explicitly said that any language could be used for mappings (though we provided an example “Model Transformation Language”, which was in part influenced by functional programming-esque pattern matching).
Somehow, it gradually came to be seen that a variant on our approach could satisfy the two competing camps who could simply claim that their languages were simply low-level QVT languages! Someone came up with the idea of calling the implementation of a transformation a “black box”, since any language can be used inside a black box without anyone else noticing. That seems to be the terminology used in the final standard.
Initially I was pleased by the idea that our proposal might end up the “winner”. However, slowly but surely, I started to wonder what exactly such a standard could achieve: is a standard a meaningful standard if implementations of it aren’t in any way compatible? The answer, I was forced to conclude, was “no”.
However, our inability to create a meaningful standard hid a deeper problem: none of us knew how to create transformations of remotely the size, sophistication, and flexibility that MDA would need. We couldn’t scale such transformations beyond toy examples and, in my opinion, we lacked plausible ideas for doing so. Since such transformations were a key part of MDA, QVT’s failure thus also guaranteed the failure of MDA.
Once I’d come to this realisation, I slowly wound down my involvement, concentrating instead on my PhD (about one third of my eventual thesis is, perhaps unsurprisingly, about UML-ish transformations; the other two-thirds is about programming languages, a topic rather nearer to my heart). I attended my last standardisation meeting in early 2005 and that was, more or less, the end of my involvement in UML standardisation10.
Summary
With the benefit of hindsight, I think UML had quite possibly reached not only its actual, but also its potential, peak in 2000: as a medium for software sketching, people only ever needed the basics from it. However, the standardisation community developed an ambitious vision for UML that far exceeded sketching. Whether or not that vision could ever be realised can be seen as a matter of genuine debate: what seems unarguable to me is that such a vision was deeply unsuited to any standardisation process. QVT is the most succinct example of trying to standardise what was, at best, early-stages research, with failure inevitably resulting. However, while the standardisation overreach inherent in QVT stayed largely within OMG’s confines, MDA’s failure was widely noted. Not only was MDA seen to fail, but by association it undermined the success of UML as a sketching language, turning it into the butt of jokes that it has largely remained to as these days.
I could not have guessed this at the time, but my involvement in all this taught me several valuable lessons, two of which I think are worth highlighting.
First and foremost, group dynamics can develop in such a way that reasonable optimism turns into blind optimism and expressing doubts becomes a taboo. When that happens, it is easy for the group to drift towards extreme positions that guarantee the group’s failure. The UML standardisation community became ever more invested in UML 2’s success: at first, doubting views were dismissed as referencing trivial problems; eventually such views stopped being expressed at all. The community only talked about success, even when there was significant evidence that failure was the most likely outcome11. Similarly, QVT was the wrong idea at the wrong time, but people were so desperate for success that they chose to ignore fundamental problems.
Second, when standardisation moves from “standardise what already exists” to “standardise things that we think would be good but don’t yet exist” it enters dangerous territory. I rather like research, but standards committees are about the worst possible place to do research. At best an unsatisfying lowest common denominator ends up being chosen, but at worst the process collapses. There should be no shame, in my opinion, in a standardisation process realising that it has raced ahead of where the state-of-the-art is, and that it would be better to revisit matters when meaningful progress has occurred.
I jokingly titled this post “UML: My Part in its Downfall”. Really, it’s probably more accurate to say that its downfall had been predestined before I had anything to do with it, and I probably had no observable effects on its success or failure. But I hope you found my perspective, and half-remembered memories, of this cautionary tale interesting!
Acknowledgements: thanks to Lukas Diekmann and Hillel Wayne for comments.
Footnotes
To some extent this was a more ambitious variant of CASE tools.
To some extent this was a more ambitious variant of CASE tools.
Booch was a Rational employee; Rumbaugh later joined Rational; and Rational then bought Jacobson’s company.
Booch was a Rational employee; Rumbaugh later joined Rational; and Rational then bought Jacobson’s company.
From memory, at first things like interface were hacked into UML.
Later on there was a movement to allow UML “profiles”, which were different
subsets of UML tailored to better represent different languages. I’m not sure
that profiles achieved much recognition outside OMG circles.
From memory, at first things like interface were hacked into UML.
Later on there was a movement to allow UML “profiles”, which were different
subsets of UML tailored to better represent different languages. I’m not sure
that profiles achieved much recognition outside OMG circles.
The initial grouping was called “pUML” (precise UML). From that a final subgroup formed called 2U. This happened to be when I was starting to get involved with things. I wondered how much an appropriate domain name might be, so I contacted the domain squatters receiving back the following email:
Thank you for your interest in our premium domains.
The current asking price is: 2u.org $2900
It was a ridiculous quote (about $4,500 in today’s money) so I replied with a commensurately ridiculous faux-naive email:
My colleagues inform me that although the current asking price is marginally beyond our department’s budget, we can still make an offer of $20 with a possible extension to $25 in further negotiations.
At the time we all found this hilarious!
The initial grouping was called “pUML” (precise UML). From that a final subgroup formed called 2U. This happened to be when I was starting to get involved with things. I wondered how much an appropriate domain name might be, so I contacted the domain squatters receiving back the following email:
Thank you for your interest in our premium domains.
The current asking price is: 2u.org $2900
It was a ridiculous quote (about $4,500 in today’s money) so I replied with a commensurately ridiculous faux-naive email:
My colleagues inform me that although the current asking price is marginally beyond our department’s budget, we can still make an offer of $20 with a possible extension to $25 in further negotiations.
At the time we all found this hilarious!
A subset of UML already existed: MOF. That served as a useful conceptual basis for the work I’m talking about.
A subset of UML already existed: MOF. That served as a useful conceptual basis for the work I’m talking about.
The whole document has a noticeable bias towards “middleware”, a now largely discredited term. I very strongly suspect that this reflects the active involvement of the OMG, whose pre-UML bread and butter had been standardising CORBA.
The whole document has a noticeable bias towards “middleware”, a now largely discredited term. I very strongly suspect that this reflects the active involvement of the OMG, whose pre-UML bread and butter had been standardising CORBA.
Literally. I had to double the amount of RAM in my computer in order to run OptimalJ.
Literally. I had to double the amount of RAM in my computer in order to run OptimalJ.
Although a non-profit, it seemed to me that, like most organisations, the OMG was keen to ensure it not only had a long-term plan for surviving but, preferably, growing.
Although a non-profit, it seemed to me that, like most organisations, the OMG was keen to ensure it not only had a long-term plan for surviving but, preferably, growing.
My memory on the exact numbers is a bit fuzzy. I think there were actually 10 or 11 proposals, but 2 or 3 proposals from French organisations were merged into one (but perhaps this happened before the official deadline?). Other than their nationality, the various French proposals shared nothing in common, so their collective stance kept changing depending on who was representing the group at any given point in time. This was highly amusing, but indicative of an ineffective standardisation process.
My memory on the exact numbers is a bit fuzzy. I think there were actually 10 or 11 proposals, but 2 or 3 proposals from French organisations were merged into one (but perhaps this happened before the official deadline?). Other than their nationality, the various French proposals shared nothing in common, so their collective stance kept changing depending on who was representing the group at any given point in time. This was highly amusing, but indicative of an ineffective standardisation process.
Astonishingly, people in the small UML community associated my name with QVT for years afterwards. Though not always. In about 2012, I remember an important Professor who heard me mention QVT explain to me what the text actually meant — quoting text at me which I had written, and which did not mean what they thought it meant! I tried not to laugh.
Astonishingly, people in the small UML community associated my name with QVT for years afterwards. Though not always. In about 2012, I remember an important Professor who heard me mention QVT explain to me what the text actually meant — quoting text at me which I had written, and which did not mean what they thought it meant! I tried not to laugh.
In the standardisation community, the visible lack of progress towards the MDA vision became ever harder to explain away. Astonishingly, some members knew who was to blame — normal programmers. Yes, somehow, people who had no influence on MDA were managing to stop MDA! Validating the idea that history repeats as farce, this ridiculous variant of the Dolchstoßlegende was not universally shared in the standardisation community, but the fact that anyone said it out loud still boggles my mind two decades on. It was a sure sign that the MDA vision was failing.
In the standardisation community, the visible lack of progress towards the MDA vision became ever harder to explain away. Astonishingly, some members knew who was to blame — normal programmers. Yes, somehow, people who had no influence on MDA were managing to stop MDA! Validating the idea that history repeats as farce, this ridiculous variant of the Dolchstoßlegende was not universally shared in the standardisation community, but the fact that anyone said it out loud still boggles my mind two decades on. It was a sure sign that the MDA vision was failing.