Test-case reducers are less well known than they should be, and those who are aware of them don’t always realise the variety of ways we can use – perhaps even abuse! – them. In this post, I’m going to explore some of the things I’ve learnt while using these wonderful tools. I’ll start at the basics, because the idea is so simple that it can be hard to believe it works.
I’ll then work my way up to a deeper surprise. Test-case reducers try to reduce the length of an input, but we can force them to take into account additional factors such as how often an error occurs, or the number of instructions executed. Depending on the problem you’re trying to debug, this can make a huge difference to the real-world effectiveness of test-case reducers.
I don’t expect that anything in this post will surprise experts, but since I learnt this stuff the hard way, perhaps others will benefit from having some of it in one place.
Test-case reduction
Imagine we have written a program that crashes on a large input, and we don’t know what part of the input causes the crash: what can we do?
Most of us will probably start with debugging our program using classic techniques, gradually
moving from the quick and dirty (printf) to the more principled (debuggers) to – if
we’re desperate and experienced – “exotic” tools (sanitisers, valgrind, etc).
Every programmer ends up with a set of debugging tools and
techniques they reach for, some more effective1 than others.
One technique that is used less often than it probably should be is reducing the size of the input. In nearly all cases, the smaller an input is, the easier it is for us to work out why it’s leading to problems.
Reduction can be manual. We can load an input into a text editor, remove a portion of it, and then see if the new, smaller, input still causes a crash.
Unsurprisingly, as easily-bored humans with limited vision, we tend to miss many opportunities for reduction when we do so manually. It’s also often the case that deleting part of an input stops the program crashing in the way we were investigating: the reduced program might run to completion, or throw a different, correct and expected, error on the new input. Even worse, at some point one realises that deleting portion A of the input doesn’t achieve the effect we want, but deleting disjoint portions A and B does: how big is the search space of deletions?! A Sisyphean future beckons.
Test-case reducers
Fortunately, there are tools that automate the process of reducing test cases: test-case reducers2. These take a program, an input, and an interestingness test. The test-case reducer tries ever shorter versions of the input, and the interestingness test tells the reducer whether those shorter versions still trigger the problem you care about. Test-case reducers can be astonishingly effective – 95-99% reductions are common – and often make debugging vastly easier.
Test-case reducers can sound like they’re magic: how can a tool know what parts of the input to remove? To make things even worse, the community that has most thoroughly embraced them are compiler authors, who many programmers think of as being an impossibly skilled elite3. It seems to me that the combination of these two things has put many people off from trying such tools.
The good news is that test-case reducers are not magic. The easiest way to see that is by writing one. Let’s imagine that I’ve written this program which reads words in from a file:
import sys for l in open(sys.argv[1]): if len(l) > 25: print("Word too long\n")
When I run this on my machine with /usr/share/dict/words it prints a warning:
$ python3 t.py /usr/share/dict/words Word too long
For the sake of the example, let’s pretend that seeing that warning is an “error” and we haven’t been able to work out why it crashes using traditional debugging techniques. Can a test-case reducer help us?
The first thing we need to do is define our interestingness test. I’ll deliberately follow the conventions of the test-case reducers I’m familiar with and say that an interestingness test is a program which:
- Returns 0 if the input is “interesting” – that is, the input manifests the error we are interested in – and we should use this reduced input going forward.
- Returns non-0 if the input is “uninteresting” and we need to try a different reduction.
I’m going to write a simple4 shell script that takes a filename in as the first argument, runs my program above, and checks if it produces “Word too long” as its output. If it does, my interestingness test will return 0; if not it will return 1.
#! /bin/sh if python3 t.py "$1" | grep "Word too long" > /dev/null; then exit 0 else exit 1 fi
Now we need to do the hard part: the reducer! Fortunately it’s not too difficult:
#! /usr/bin/env python3 import subprocess, sys, tempfile cur = [x.rstrip() for x in list(open(sys.argv[2]))] i = 0 while i < len(cur): with tempfile.NamedTemporaryFile(mode="w") as p: cnd = cur[:] del cnd[i] p.write("\n".join(cnd)) p.flush() if subprocess.run([sys.argv[1], p.name]).returncode == 0: cur = cnd else: i += 1 print("\n".join(cur))
In essence, this first loads in the text input and splits it into lines
(cur). Then it loops over the input. Each iteration creates a candidate
input (cnd), with one line of input removed (del cnd[i]) relative to
the previous starting point. We create a temporary file, write the candidate
input to it, and run our interestingness test. If it returns 0, we keep the
candidate as our new starting point (cur=cnd) or try the next line (i+=1)
otherwise. When no more reductions are possible, the reduced input is
printed to stdout.
To say this implementation is slow is an understatement, but if I run it, it eventually5 prints out:
$ python3 reducer.py ./interestingness.sh /usr/share/dict/words antidisestablishmentarianism
When I first came across the idea of test-case reducers, I was briefly sceptical: how can something so simple do anything useful? Indeed, the example above might make the whole idea seem trivial: the “error” in my original program was so blindingly obvious that I surely didn’t need any of this additional machinery! In my opinion, thinking in that way can blind one to the key idea of test-case reduction: my reducer has no understanding of my interestingness test or, by extension, the underlying program the interestingness test is running. In other words, test-case reduction has done something useful despite having almost no understanding of why what it’s doing is useful.
This lack of understanding is the key to the success of test-case reducers. I
can run my test-case reducer on any text file, and it will work6. As a quick
proof, I asked my favourite LLM to generate me a reasonably sized C program
that might be amenable to test-case reduction, taking the very first thing
it gave me. The problem in this case is a classic example: a program which
unexpectedly produces two outputs in two different configurations (FAST=0 and
FAST=1). The C file is 78 lines long and I defined the following
interestingness test:
#! /bin/sh set -eu cp "$1" t.c cc -std=c99 -O2 -DFAST=0 t.c -o slow cc -std=c99 -O2 -DFAST=1 t.c -o fast slow_out="$(timeout 1s ./slow)" || exit 1 fast_out="$(timeout 1s ./fast)" || exit 1 test "$slow_out" = "0d754a56" || exit 1 test "$fast_out" != "0d754a56" || exit 1
I’ll come back to why that’s longer than our first interestingness test a little bit later. I then made one quick change to my reducer:
c = subprocess.run([sys.argv[1], p.name], stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL)
to avoid output from subcommands confusing me, and then ran the reducer:
$ python3 reducer.py ./interestingness.sh t.c > t2.c $ wc -l t2.c 54
The reducer took under 10 seconds to run, and in that short amount of time reduced the size of the input by 30% (by lines-of-code)! And, yes, it really did preserve the error I cared about.
The great thing about reducers is that if you’re willing to run them for longer,
they can do even better. Let’s make one very simple change to our reducer:
every time we find an interesting input, we take the new input, and start
deleting lines from the start: in other words, we are now able to retry
lines which we could not previously remove. All it needs us to add is i=0 at
the appropriate point:
if c.returncode == 0: cur = cnd i = 0
It now takes almost 10 times longer to run, but it shaves another 3 lines off the reduced output.
As you can imagine, further enhancements of the reducer do better and better jobs. I’m not going to bore you, or me, with them, because we can use off-the-shelf reducers which do all the tricks one might think of — and more!
I’m particularly fond of Shrink Ray, which as well as having a number of powerful and sensible reduction rules also runs test-case reduction in parallel:
$ pipx install shrinkray $ shrinkray --no-clang-delta ./interesting.sh t.c
By adding --no-clang-delta I’m preventing Shrink Ray from using any special
knowledge it has of C. In other words, I’m making it as ignorant of the
semantics of what it’s reducing as the simple reducer I wrote7.
Shrink Ray has a nice UI, which is good, because it chugs away on our example
for a while:
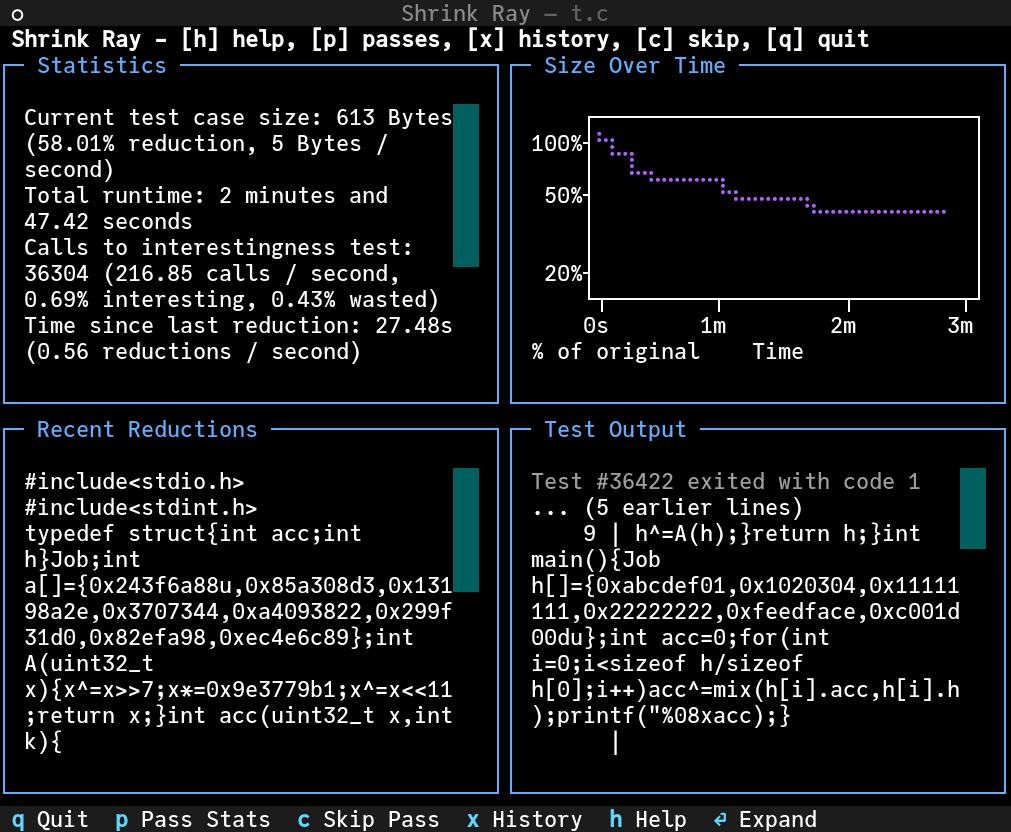
As you would expect – and bearing in mind the logarithmic y-axis in the graph – it inevitably hits diminishing returns after a while, so although it’s done a lot of reduction in a small number of minutes, it takes some tens of minutes to fully exhaust its arsenal. After about 15 minutes, it finishes, having managed to reduce the input by over 60% (in terms of bytes)! It’s worth restating how impressive this is: I gave it a random C program, a small shell script, and it reduced it enough to make debugging a lot easier.
Shrink Ray has all sorts of clever tricks up its sleeve. Some are fairly obvious – it knows standard comment syntaxes, for example, and will try removing those early on – but some are surprising. My favourite is when it starts reducing integers to smaller values, which often makes debugging surprisingly easier. I highly recommend watching it run, because seeing the reductions it attempts is illuminating.
What I find particularly satisfying is when Shrink Ray manages to find a small number of reductions that suddenly unlock many further reductions. Here’s a screenshot from a random recent reduction I ran:
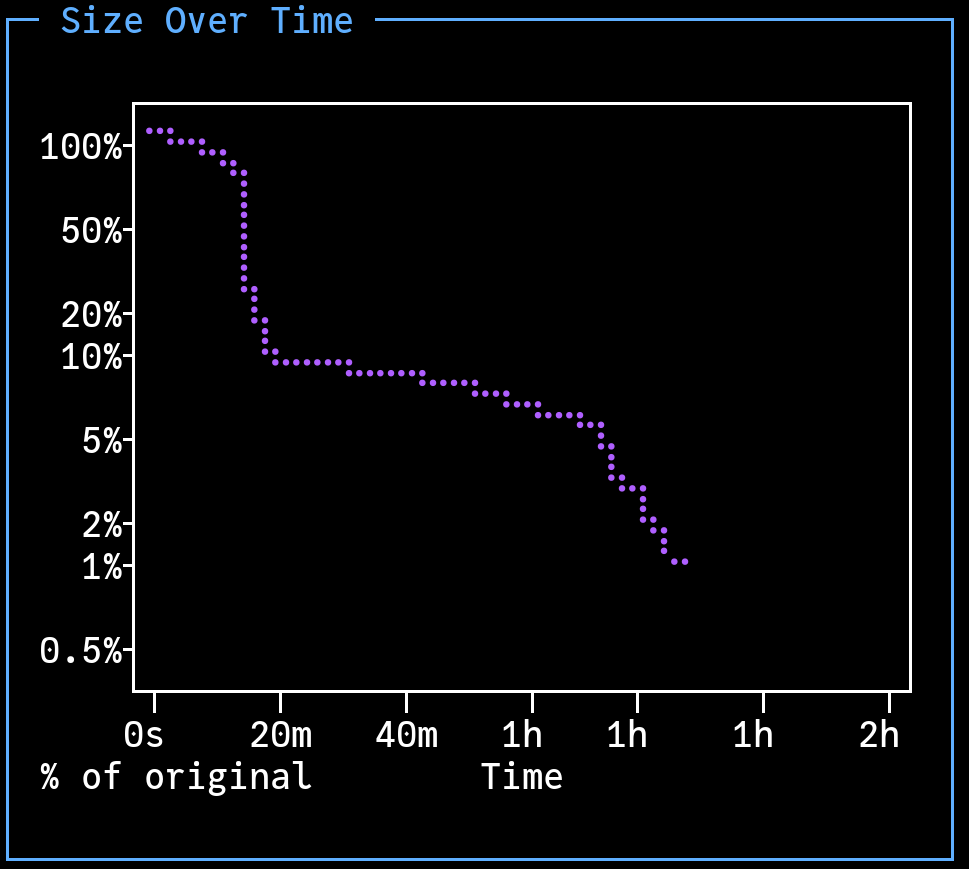
I had spent quite some time trying to debug that particular input, and managed to do nothing but drown myself in detail. After about 20 minutes, Shrink Ray found the magic key that allowed the input to be reduced in size by 90%, then kept on chipping away until it was reduced by 99%. Suddenly the bug popped out at me. This is a common experience in test-case reduction.
Interestingness tests can be hard to write
Let’s go back to the second interestingness test I defined:
#! /bin/sh set -eu cp "$1" t.c cc -std=c99 -O2 -DFAST=0 t.c -o slow cc -std=c99 -O2 -DFAST=1 t.c -o fast slow_out="$(timeout 1s ./slow)" || exit 1 fast_out="$(timeout 1s ./fast)" || exit 1 test "$slow_out" = "0d754a56" || exit 1 test "$fast_out" != "0d754a56" || exit 1
That might look a bit more complex than you were expecting: the reason for that is that bitter experience has shown me how easy it is to write suboptimal, mostly flat-out wrong, interestingness tests. Even this short example embeds several important lessons.
First and foremost, test-case reducers are literal drivers of interestingness tests.
It’s very easy to make the interestingness test accept things it shouldn’t,
which will then cause the test-case reducer to reduce past the
point where you wanted it to stop. Over-reduction is so common that Shrink
Ray explicitly checks whether an interestingness test accepts an empty
input — I hit this check worryingly often. In the example above, it might
seem that all I needed to do was check that the two compiled programs
have different outputs (test "$slow_out" != "$fast_out"). However, that would
allow unimportant, probably misleading, differences in output to be classified as
interesting. The first check test "$slow_out" = "0d754a56" ensures that
the slow version of the program really does what it should, making that
outcome much less likely8.
Second, the faster your test case runs, the faster the overall reduction takes. A test-case reducer can run the interestingness test hundreds of times a second if it’s fast enough! Since even moderately sized examples can lead to hundreds of thousands of reduction attempts, this can really add up. Particularly for large inputs – where the reducer will have to try many attempts – I’ve found it worthwhile to make sure the interestingness test is somewhat optimised. Some of the “optimisations” are unconventional: I recently sped an interestingness test up by ~3x by turning off the automatic creation of core dump files!
Third, test-case reducers will happily remove lines like i-=1, turning
terminating programs into non-terminating programs. If you’re wondering why
your reducer isn’t making progress, this is almost certainly why. Shrink Ray
has a global timeout but, as in the above example, I often run the
test input more than once. Because interestingness tests need to run as fast
as possible, I set “sub timeouts” to detect uninteresting
inputs as soon as possible. It can be tempting to set a very conservative timeout,
say 60 seconds, but if the program we’re looking at runs in 0.1s, we’re slowing
our overall reduction down by orders of magnitude for little or, more
likely no, gain. I tend to quickly measure the program before reduction: if
it’s really fast, I’ll round the timeout up to a second or two; otherwise
I’ll set a timeout of roughly 1.5-2x its initial running time.
A final major factor one needs to consider is that reducers like Shrink Ray run interestingness tests in parallel9. Fortunately, in this particular case, Shrink Ray already does all I need: it runs each interestingness test in a temporary directory (which it also automatically clears up). That’s often not sufficient, alas, but what one needs to do varies on a case-by-case basis.
Using interestingness to encourage determinism
Imagine I have a troublesome input which, somewhere within it, contains this fragment:
x = 1 y = len([]) if random.random() < 0.33: print(x / y)
The obvious problem with this is that it contains a division by zero
(len([])==0). The less obvious problem is that this troublesome outcome only
occurs in around 1/3 of runs. Nondeterministic bugs are the bane of a programmer’s
life: since the bug appears and disappears at random, it makes testing hypotheses
about an error even more difficult and time-consuming than normal.
If we’re lucky, at some point our reducer will remove the random.random()
call (it might reduce the if line entirely10 or replace
part of the conditional). In so doing, it will turn a nondeterministic
error into a deterministic error, making the bug easier to understand and fix.
It took me a little while to realise that test-case reducers can reduce the level of nondeterminism in inputs — often to zero! Unfortunately, real-world nondeterminism can sometimes be hard to remove. Nondeterministic bugs often involve multiple parts of an input interacting in an unfortunate way. It’s easy to reduce the input in a way that does not improve, or even worsens, the frequency with which a bug occurs. I see this happening quite often when debugging yk.
The basic problem is that a test-case reducer is effectively a hill-climbing algorithm that uses the length of input as a proxy for “is better”. This has two related problems:
- Hill climbing approaches are prone to getting stuck in local optima.
- Shorter inputs aren’t always better when searching for an error.
We could “solve” the first point by exploring the full tree of reductions, rather than one path through that tree. However, in general, the search space would become comically large: we have little choice but to accept a pragmatic compromise11. Fortunately, though, we can write our interestingness test in a way which integrates additional factors into the search, implicitly bending it away from solely considering the length of input12.
When I have a nondeterministic bug on my hands, I try an interestingness test which runs the input multiple times and accepts it if the error I’m interested in occurs at least once. For the above example I might write this interestingness test:
#! /bin/sh i=3 while [ "$i" -gt 0 ]; do t="$(mktemp)" python3 "$1" >"$t" 2>&1 if [ "$?" -eq 1 ] && grep ZeroDivisionError "$t"; then rm "$t" exit 0 fi rm "$t" i=$((i-1)) done exit 1
I tend not to obsess over the number of repetitions. I vaguely guess how often the error I’ve seen occurs, set an appropriate repetition count based on that, and see what Shrink Ray makes of it. It often increases the frequency with which the error occurs13.
However, this doesn’t always work. The obvious problem with this approach is that it will happily accept nondeterministic inputs. Indeed, it’s quite possible – and I’ve seen this happen many times in practice! – for the level of nondeterminism to increase as reduction advances.
What I really want to do is have an interestingness test that only accepts an input if it succeeds for all n iterations:
#! /bin/sh i=3 while [ "$i" -gt 0 ]; do t="$(mktemp)" python3 "$1" > "$t" 2>&1 if [ "$?" -ne 1 ] || ! grep ZeroDivisionError "$t"; then rm "$t" exit 1 fi rm "$t" i=$((i-1)) done exit 0
If an input passes this new interestingness test, it’s much less likely to be nondeterministic. Unfortunately, the strictness of this interestingness test is more a weakness than a strength: it’s almost impossible to get Shrink Ray started with it! One of Shrink Ray’s initial tests is that the interestingness test succeeds with the initial input, but there’s only a 3.6% chance of that occurring!
Even if you’re persistent enough to get past that initial check, you might find yourself lucky to find meaningful reductions: since, as we’ve seen earlier, it’s often common for more than one initial reduction to suddenly unlock a mass of later reductions, the probabilities of meaningful reduction stack up against us.
The way I’ve traditionally worked around this is crude but effective. I start with the “accept if the error happens at least once in n runs” interestingness test. Every so often I try the current reduced input to see if the error I’m interested in is happening more often. If it does, I overwrite the interestingness test with the stricter “accept if the error happens n times in a row” test.
Intuitively what I’m doing is two-fold: I wait until I get lucky with Shrink Ray (i.e. it’s somehow found a reduction which reduces the level of nondeterminism); and, when I have got lucky, the change in interestingness test makes it far more likely that I stay lucky thereafter.
That I tend to stay lucky might seem surprising. My stricter interestingness test still allows nondeterministic inputs through, albeit with a reduced probability: my initial input, for example, has a 3.6% chance of being accepted. Fortunately, the practical effect is nearly always far less bad than that sounds. My intuition is that this is because subpaths of reductions often converge, so a “bad” reduction has a good chance of being caught later on. Whether that intuition is right or not, this approach has worked well for me in practice.
The “compare to a global counter” technique
Manually interfering with reduction is powerful, but fragile: I have to babysit Shrink Ray, and I can easily miss the point when I should interfere. It took me some time to realise that what I’m really doing is steering the reducer to a property other than input length and that I can construct a single interestingness test to enforce this.
It’s easiest to see this using a very different example. When debugging problems in yk, the length of a trace – which for the purposes of this blog we can think of as “the number of instructions the program executes” – that yk produces is far more important to me than the length of the input. I thus really want to favour inputs that produce smaller traces.
Unfortunately, Shrink Ray has no principled way for me to express this. Fortunately, I have no principles, and use unsafe hacks like this:
t="$(mktemp)" YKD_LOG_IR="$t:jit-asm" /path/to/interpreter "$1" if [ "$?" -ne 139 ]; then rm "$t" exit 1 fi new_len="$(wc -l < "$t" | tr -d " ")" if [ ! -f /tmp/global_best ]; then echo "$new_len" > /tmp/global_best fi old_len="$(cat /tmp/global_best)" if [ "$new_len" -gt "$old_len" ]; then rm "$t" exit 1 fi echo "$new_len" > /tmp/global_best rm "$t"
Let me state upfront that this interestingness test is the worst code I’ve ever knowingly published on my website. First, it’s completely unsound in the presence of parallel reductions. Second, it implicitly makes a number of (probably partly or wholly) incorrect assumptions about how the reducer calling it works. I did briefly think about rewriting the shell script to solve the first of these two worries, but the truth of the matter is that I don’t bother with such matters when I’m doing test-case reduction. I’m writing short scripts that I’m going to throw away: I can tolerate a greater degree of imperfection than normal.
With that proviso in mind, let’s look at the interestingness test. In this
particular example, I was trying to debug a segfault: the interestingness test
only passes its first check if the input segfaults ("$?" -ne 139).
The second check is where things become unconventional. I want to reduce the
length of YKD_LOG=$t:jit-asm’s output. YKD_LOG writes to the file $t with
textual trace IR and machine code instructions, what yk calls jit-asm output.
The shorter the jit-asm output is, the easier it is for me to debug. wc -l
(“how many lines are in this file?”) is an almost perfect proxy for what I care
most about14.
The interestingness test therefore asks “is the number of lines in the current
trace greater than the previous lowest number of lines I’ve seen? If so, this input is
uninteresting.” That latter number is stored in /tmp/global_best.
The only subtlety here is the “greater than” part. I don’t mind the input file
getting smaller if the trace stays the same size but if the trace is even one
line longer, I want to declare the input uninteresting.
This approach, despite its defects, can be surprisingly effective. For example, I recently encountered a yk segfault where reduction led to traces of 40K lines: I gradually realised that there was just too much stuff for me to successfully debug the output. After trying, and failing, to manually interfere with reduction, I used the technique above. Shrink Ray then produced a slightly larger reduced input, but one that produced traces only 10.1K long. That’s still quite big, but within half an hour I’d worked out what the underlying bug was.
It is hopefully fairly obvious that this technique has nothing to do with yk, nor lines in logging output. One could easily use it to enforce properties such as “I want reduction to concentrate on driving down the wall-clock time of my input” or “I want reduction to drive down the level of nondeterminism” and so on.
Summary
In this post I hope I’ve shown you what test-case reducers are, what they can do for you, and how you can use them in unconventional ways. There’s much more you could read, including other surprising uses of test-case reducers (e.g. using them as fuzzers).
I also hope that I’ve shown you that test-case reducers aren’t just useful for compiler writers — I’ve used them for non-compiler things too! They really are wonderful tools that have made me much more productive, and they might do the same for you too!
Acknowledgements: Thanks to Carl Friedrich Bolz-Tereick and David MacIver for comments.
Footnotes
Both in the sense of “some tools and techniques are more effective for debugging” and “some programmers are more effective at debugging”.
Both in the sense of “some tools and techniques are more effective for debugging” and “some programmers are more effective at debugging”.
To the extent I can tell, the first test-case reducer was part of RAGS (see Section 4.3), though it seems to have been tied to SQL. More commonly, ddmin is cited as the first general test-case reducer. Honestly, I had heard of neither until researching this footnote. The first test-case reducer I, and I believe many others, heard of was creduce. Although it took me some time to get around to using creduce, the idea stuck with me almost immediately.
To the extent I can tell, the first test-case reducer was part of RAGS (see Section 4.3), though it seems to have been tied to SQL. More commonly, ddmin is cited as the first general test-case reducer. Honestly, I had heard of neither until researching this footnote. The first test-case reducer I, and I believe many others, heard of was creduce. Although it took me some time to get around to using creduce, the idea stuck with me almost immediately.
One of the services I render to society is diminishing this stereotype. Worryingly for me, I manage this without doing anything other than opening my mouth.
One of the services I render to society is diminishing this stereotype. Worryingly for me, I manage this without doing anything other than opening my mouth.
This script can be made smaller, but writing it out like this makes it more likely that it will be understood.
This script can be made smaller, but writing it out like this makes it more likely that it will be understood.
With /usr/share/dict/words on my desktop, this takes almost
exactly 3 hours!
With /usr/share/dict/words on my desktop, this takes almost
exactly 3 hours!
Although it will only do something useful on files with more than one line. I’m sure readers can easily work out how to generalise that!
Although it will only do something useful on files with more than one line. I’m sure readers can easily work out how to generalise that!
Teaching a reducer about a specific language’s syntax and semantics makes it even more effective.
Teaching a reducer about a specific language’s syntax and semantics makes it even more effective.
Without looking at the input file, this wouldn’t quite be a guarantee that over-reduction couldn’t happen. Often interestingness tests require a balance of probabilities: “could a weird case happen? If I think no, then try a simpler interestingness test and see what happens.”
Without looking at the input file, this wouldn’t quite be a guarantee that over-reduction couldn’t happen. Often interestingness tests require a balance of probabilities: “could a weird case happen? If I think no, then try a simpler interestingness test and see what happens.”
I’m lucky to have access to a 72 core server, which is immensely helpful when reducing large inputs: Shrink Ray is often able to utilise all those cores.
I’m lucky to have access to a 72 core server, which is immensely helpful when reducing large inputs: Shrink Ray is often able to utilise all those cores.
This is where a sophisticated reducer is useful. They do things
like adjust indentation to make it less likely that a reduced input is
syntactically incorrect; and they try replacing expressions such as
random.random() with a constant.
This is where a sophisticated reducer is useful. They do things
like adjust indentation to make it less likely that a reduced input is
syntactically incorrect; and they try replacing expressions such as
random.random() with a constant.
Shrink Ray allows you to manually wind the clock back and start from a previous reduction. That’s still very different to automatically exploring the entire search space.
Shrink Ray allows you to manually wind the clock back and start from a previous reduction. That’s still very different to automatically exploring the entire search space.
I think the idea I’m proposing can be seen as a variant of cause reduction, though I have ended up using very different “additional” factors.
I think the idea I’m proposing can be seen as a variant of cause reduction, though I have ended up using very different “additional” factors.
In this contrived example, Shrink Ray is almost too good: it
eventually reduces the input to 0/0!
In this contrived example, Shrink Ray is almost too good: it
eventually reduces the input to 0/0!
The slightly convoluted call to wc is due to the following. wc -l t
outputs a path followed by a number. wc -l < t outputs spaces then a
number. tr -d " " deletes those spaces.
The slightly convoluted call to wc is due to the following. wc -l t
outputs a path followed by a number. wc -l < t outputs spaces then a
number. tr -d " " deletes those spaces.